I try to implement a zip and download functionality that reads out a folder on azure and zips the files inside that folder.
There are the following steps :
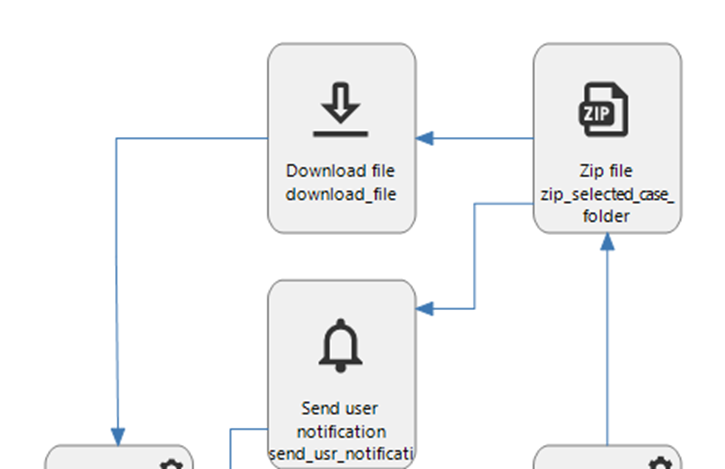
- Decision that either selects the next folder to zip or ends the process when there is no folder left to zip. This decision sets a process variable with the name of the folder. (not shown in the picture)
- This folder name is used as input for the zip process action.
- One of the output fields of the zip action is the file_data, which is assigned to a process variable that has the var_binary(max) datatype.
- This var_binary variable is the used as input for the download action that also takes the filename of the eventual file that is downloaded.
The download itself seems to be working as in that a ‘save as’ form is shown with the correct filename that can then be saved on the local machine.
However, the file that is created is empty.
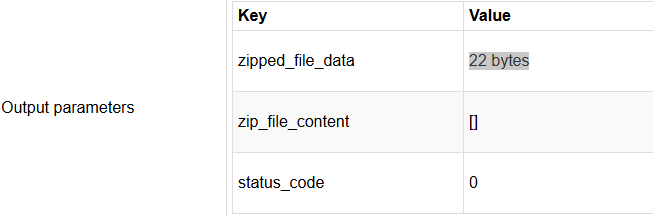
The zip functionality itself does not give any errors (status code 0 is returned) and the file_data output parameter is set but the binary data output that I can see in the process flow monitor is only 22 bytes big, which seems to suggest to me that this part already goes wrong, since I expect the data to be a bit bigger.
The input parameter of the zip action indicates that only a folder of filename is needed and that thus no additional steps are needed that proceed the zip action. The binary data output seems to suggest that we can do this in memory and put the data then inside the download functionality without having to save the zip file first.
When I fill in a folder name, I expect the content of this folder to be zipped and stored in the binary data output parameter.
Is that assumption wrong?
additional data:
- the folder is a folder on an azure storage location.
- The functionality is accessed via the browser.