


In our previous blog, we discussed why we came to the conclusion that translating natural language into a formal language is the best approach for us to create linguistic interfaces for Thinkwise applications.
It was mentioned that an existing project called Genie follows this approach and we decided to build a prototype to test whether or not Genie is the best framework for us. The purpose of this blog is to share our story about how we built our first prototype using the Insights demo application. The prototype is available at (https://nlpdemo.thinkwise.app/)
To make it more formal, for our prototype we need to construct a neural semantic parser from the Insights data model using Genie.
A semantic parser is basically a tool that can translate from natural language into a machine-understandable form. In our case, this will be a translation to the ThingTalk Virtual Assistant Programming Language (VAPL). The term neural refers to the fact that the generated semantic parser is a large neural network.
The process of constructing a neural semantic
parser roughly consists of two phases: first generate a training/validation dataset followed by the training of the neural semantic parsing network.
For these purposes Genie has two main parts:
-
Genie-Toolkit: written in javascript/typescript to generate a device description and datasets.
-
GenieNLP: a natural language processing library written in python to train and consume the neural semantic parsing network using PyTorch.
Generate a dataset using the Genie-Toolkit
Our goal was to generate the datasets directly from the Thinkwise meta-model supplemented with actual end-product data. The training algorithm for the neural semantic parser expects the datasets to have the following form:
ID <tab> Natural Language <tab> ThingtalkBefore genie can actually generate our datasets, a few pre-processing steps are required. The first being the creation of a so-called device description.
A device in this respect is a broad concept and can mean anything that can be controlled through an API. A device can have two types of functions: query and action.
In this respect, the Insights application can be seen as a device that can have functions like: starting a task, opening a screen, or applying a filter.
The device definition is a collection of functions, entities, properties, relationships, and natural language annotations that describes our application. The natural language annotations are used to inform Genie about how entities and properties can be used in natural language.
For example, in the Insights demo application, the table "project" can be seen as such an entity and the columns as its properties. Suited natural language annotations for the column project.finished_on_date which Genie can use for language generation are:
- finished on date -> Show projects with finished on date before January first 2021.
- completed # -> Show me all projects that were completed last year.
- been finalized as of # -> Find projects which have been finalized as of January first 2021.
For completeness, it must be mentioned that Genie does not directly construct natural language from the device description, but will first generate Thingtalk expressions that in turn are parsed into natural language.
Using the finished_on_date example, Genie may generate the following Thingtalk:
@Insights . project ( ) filter finished_on_date <= $start_of ( year ) && finished_on_date >= $start_of ( year ) - 1 year ;which in turn is parsed into "show me all projects that were completed last year"
Construct a device description using Schema.org
Because the datasets to train the neural semantic parser are derived from the device description it is of the utmost importance that it is of high quality. Luckily Genie comes with several functions to aid in this process.
For relational data sources, Genie has starter code that can be used to generate device descriptions from any data source that follows the Schema.org standard.
Schema.org is a collaboration between Google, Bing, Yandex, and Yahoo. It provides schemas for structured data that webmasters can use to inform search engines about the information that is provided by their website.
For our prototype, we decided to use the Schema.org starter to create our first neural semantic parser for the Insights application.
By choosing to use the Schema.org starter, we did limit our first prototype to filter queries only. We reasoned that this would not be a problem for our prototype, because filter queries are probably the hardest to transform to natural language.
There are two main reasons for this. First filters are based on data models that can differ a lot between applications and are not created with linguistic interfaces in mind. Second, translations in the Thinkwise meta-model are primarily for graphical user interfaces and may not always be suitable for natural language generation.
Thinkwise meta-model to Schema.org conversion
In the process of translating the Thinkwise meta-model, or more precisely the data model because we are only focused on filtering, to a device description we soon discovered that the terminology used on https://schema.org was not always suited for our situation. We wanted to use the Thinkwise meta-model translations instead.
To overcome this problem we needed to generate our own definition following the Schema.org standard that can replace the one defined in JSON-LD on https://schema.org/version/latest/schemaorg-current-https.jsonld
We thus needed something that can translate a Thinkwise data model to a correctly formatted JSON-LD file.
JSON-LD is a superset of JSON for Linked Data and is one of the formats in which RDF graphs can be expressed. Schema.org is in fact an RDF graph in a standardized format. RDF or The Resource Description Framework is a method for modeling information using triples. Each triple is in the form of subject-predicate-object. For instance:
<finished_on_date,type,property>defines finished_on_date as being of type property. All sorts of relationships can be modeled by defining such a triple in which the > predicate informs about how subject and object are related.
We found two useful R packages, rdflib and jsonld, and created an R script that can transform the Thinkwise data model to an RDF graph, which in turn can be exported to JSON-LD.
Script for transforming the Insights data model into Schema.org JSON-LD
The first step in creating our own Schema.org representation of the Insights data model, is by reading all relevant data from the Insights meta-model. To prevent ending up with a dataset that has too much unnecessary data or data that can pollute our dataset (e.g. a large number of HTML tags in a varchar column) it was decided to only include tables/views that are reachable from the menu, only add columns that are visible on a form, and filter out columns that have domains with HTML components or other large pieces of text.
The Schema.org standard only has two types of objects, classes, and properties. Classes (tables/views) have properties (columns), but properties are also always an instance of some class. This implies that a property is always a reference to some class.
Create Tree structure
For an easier conversion from the data model to RDF, the data model is first converted to a list of tree structures using the data.tree R package.
Each table/view that has a menu entry is used as starting point for such a tree. The tree is then built recursively following the references defined in the Thinkwise meta-model and connecting each table/view to the one it is referenced from (parent). The resulting tree is then added to a list.
Each node in a tree then represents a Schema.org Class and edges define how classes are used as a property in other classes.
During the tree building process, each tree node is also augmented with:
-
Column Properties
-
Primary Key
-
Foreign Key
-
Datatype
-
Translation
- For Schema.org transformed to camel-case with lowercase first letter.
-
Calculated field query
-
-
In the case of a referenced table their reference columns
- Needed for sampling end-product data
-
Table translation,
-
Used as class name
- Camel cased with uppercase first letter
-
-
Tables lookup column
- A name property is mandatory for Schema.org classes, and the lookup value is used for that
The result is a list of trees that can all be joined together to form a single representation of how all the tables and views that are accessible through the menu are connected to each other, together with their relevant properties and Schema.org transformations.
Build RDF graph and export to JSON-LD
Creating an RDF graph from the tree structure is now easy. For every leaf, the tree is traversed upwards to the root node. At each traversal, table translations are added as classes, column translations as properties, and edges are transformed to triplets that define how classes are connected
When done, rdflib can be used to export the graph to a JSON-LD file. The next figure gives a small example of how the resulting JSON-LD looks like.
The finished_on_date column is used as a property for two classes, Subproject and Project, and that finished_on_date itself is of the Date class.
{
"@id": "http://Schema.org/finishedOnDate",
"@type": "rdf:Property",
"http://Schema.org/domainIncludes": [
{
"@id": "http://Schema.org/Subproject"
},
{
"@id": "http://Schema.org/Project"
}
],
"http://Schema.org/rangeIncludes": {
"@id": "http://Schema.org/Date"
}
},Sample product data
As mentioned earlier the prototype should be generated from both metadata and actual end-product data. In the Genie Schema.org starter, actual end-product data can be used when it is presented in a single nested JSON file.
Because we already have a tree structure containing all the information needed for querying an end-product database, the easiest way to sample data from the database was by adding it to that same tree structure. This directly gives us the required nesting.
By traversing the tree depth-first, queries can be generated for each node. In the case of referenced (detail) nodes, the primary key values from their parent were used in the where clause to ensure data integrity. Similar foreign key values were used for lookup references.
The final result is a JSON file containing referenced data as nested structures.
Import end-user data
Before Genie can use our end-user data, Genie must parse the large JSON file into several smaller ones. A tab separated file is created for every property and a JSON for each class, or entity as they are now known in ThingTalk.
These files are later used to sample data for the post-processing of the device description and for augmenting the training/validation datasets.
Creating the device description
Because we now have the Schema.org translation of our data model and the required end user-data, we are ready for Genie to create the device description. In the first stage of this process, Genie will use the Schema.org JSON-LD file to create a first device description that only holds the structure of the Insights data model.
The following shows an example of how the Country table is translated to a ThingTalk definition in the device description.
list query Country extends Thing(out id : Entity(Insights:Country)
#_[canonical={
base=["name"],
passive_verb=["called", "named"]
}]
#[unique=true]
#[filterable=true]
#[org_schema_has_data=true],
out customer : Array(Entity(Insights:Customer))
#_[canonical={
default="property",
base=["customers"]
}]
#[org_schema_type="Customer"]
#[org_schema_has_data=true],
out employee : Array(Entity(Insights:Employee))
#_[canonical={
default="property",
base=["employees"]
}]
#[org_schema_type="Employee"]
#[org_schema_has_data=true],
out euMember : Boolean
#_[canonical={
default="property",
property_true=["eu member"],
base=["eu member"]
}]
#[org_schema_type="Boolean"]
#[org_schema_has_data=true])
#_[canonical="country"]
#_[confirmation="country"]
#[confirm=false]
#[minimal_projection=["id"]]
#[org_schema_has_data=true]
#[org_schema_has_name=true];Because we dit not use our end-product data in this step, only the default annotation tags (#_[canonical=] arrays ) were added. Meaning that at this stage there is no extra information about how properties can be referenced in sentences, besides what can be known from the specified datatype.
Post-processing using Genie Auto-Annotate
To enrich the information present in the device description, Genie can use pre-trained transformer models (BERT and BART) for generating paraphrases. Genie can combine the information present in the device description together with end-user data samples to do the following:
-
Find synonyms for property names
-
Find synonyms for table names
-
Use both the original and synonym terms to generate sentences
-
Analyze those sentences to find out different ways how terms can be used in sentences
-
Extend the device description with synonyms and alternative uses.
For instance the property lastName of employee is automatically enhanced to:
out lastName : String
#_[canonical={
default=["property"],
base=["last name"],
property=["last name", "the surname #", "the last name of #", "the last name #"],
verb=["named #", "called #"],
adjective=["#"],
passive_verb=["named #"],
preposition=["by the name of #"],
base_projection=["last name"],
verb_projection=["named", "called"],
passive_verb_projection=["named"],
preposition_projection=[]
}]
#[org_schema_type="last_name"]
#[string_values="Insights:employee_last_name"]
#[org_schema_has_data=true],Create synthetic dataset from the device description
Using the (auto-annotated) device description file, a set containing synthetic data can be generated. This dataset contains both Thingtalk expressions and their natural language translation. The next example shows a natural language sentence and the corresponding Thingtalk expression to filter the project table on the name of a subproject:
please enumerate projects that have subproject GENERIC_ENTITY_Insights:Subproject_0
@Insights . Project ( ) filter contains ( subproject , GENERIC_ENTITY_Insights:Subproject_0 ) ;GENERIC_ENTITY_Insights:Subproject_0 is an example of a placeholder, in this case for the name of a subproject. These placeholders are replaced by actual end-user data in the next step.
Augment synthetic dataset with product data
To replace the placeholder in our synthetic dataset, Genie can be used to sample replacement values from our end-product data files and create our final augmented dataset.
The next example shows a sentence where the meeting table is filtered on customer "vd installation"
please search for an appointments that are customer vd installation @Insights . meeting ( ) filter customer == null ^^Insights:customer ( " vd installation " ) ;Note that because natural language is generated from the Thingtalk code using templates, sentences may not always be 100% correct as this example shows.
Train neural semantic parser
Now that we have our augmented dataset, the next step to take is to split this dataset into a training and an evaluation part and start training the neural semantic parser.
The training and evaluation datasets were transferred to an Amazon ec2 p3 instance (V100 GPU) for the training phase. A fast GPU is necessary because the neural semantic parser is in fact a very large neural network, which would take several days to train on a CPU.
The neural semantic parser was then trained for 50.000 iterations, which took about five hours to complete. The final result is a 3.3GB large PyTorch model with 406,312,960 parameters.
Directly generate the device description and data sample files
At this point in time, we were able to train a semantic parser but were not really satisfied with the quality of the natural language to ThingTalk translations. One of the things that bothered us was the fact that by using the Schema.org starter, we could only generate ThingTalk using camel-cased translations and not their actual database names. This will make it harder for a parser to translate it back to the Thinkwise model.
We also wanted to test if it was possible to have more control over how the initial device description was created. Therefore it was decided to see if we could skip the whole Schema.org transformation and manually create the device description file.
We argued that it would not be that hard to change the R script so that it can generate a device description instead of a JSON-LD file. This is because Genie is basically transforming one tree structure (JSON-LD), into another (device description). The JSON-LD file in turn is exported from an RDF graph which was created from a tree structure that was created from the Thinkwise meta-model.
It seemed we had several redundant steps and in practice, it turned out that we could skip most of them and build the device description directly from the data.tree object in our R script.
Similarly, we argued that because all the end product data is already present in the data.tree object, it only needs to be exported to the correct formats (JSON and TSV depending on class or property), there is no need for the large JSON file.
By simplifying the whole process we are now capable of using the Thinkwise meta-model and end-product data to directly generate a device description and data sample files. Genie is still used for the post-processing of the device description and for generating and augmenting the datasets.
The next figure gives an overview of the whole process of generating datasets without the Schema.org conversion.
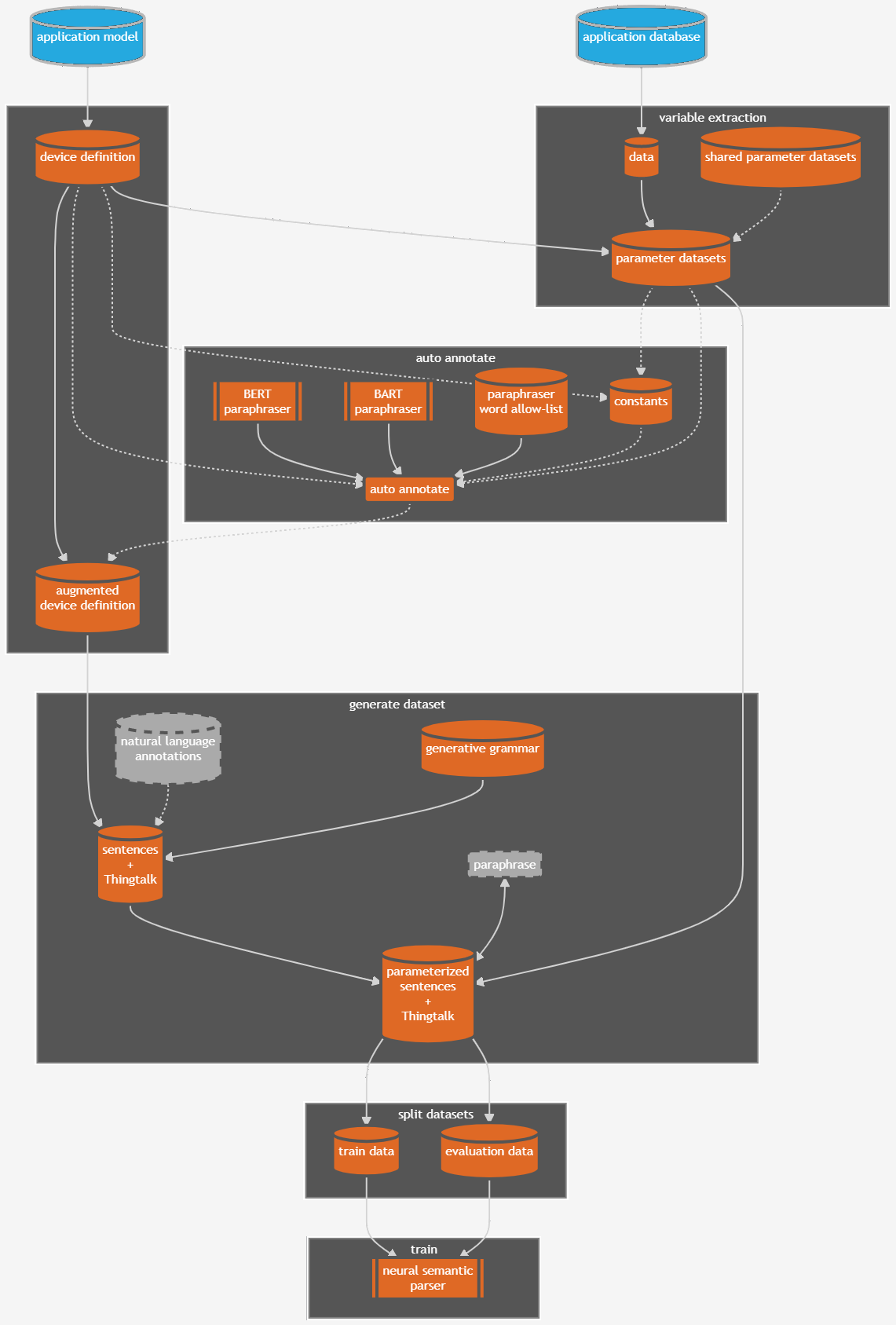
Further improving the training/validation data
Even though the natural language sentences are generated from the ThingTalk syntax using advanced templates, the final result is not always satisfying. Deterministic templates will never be capable to perfectly capture all language quirks.
There are however several options to enhance the generated dataset:
-
Manually alter the canonical annotations in the device descriptions.
- You can for instance remove certain unwanted synonyms or add domain-specific uses for properties.
-
Manually improve the datasets
- Add sentences that were not added automatically
- Correct existing sentences
-
Use a paraphraser neural network
- Fully automatic process that can, for each sentence in the dataset, generate similar sentences that are more syntactical correct
- Paraphraser models may even be fine-tuned to a specific domain to increase the probability that domain-specific terms will be present in the generated sentences.
Paraphrasing training data
Genie comes with an option to apply the third option mentioned above. For every sentence generated with the templates, the Genie paraphraser model will come up with a number of alternative ones. To prevent ending up with sentences that have a different meaning than the original, a neural semantic parser trained on an initial dataset with template sentences only (our first prototype) is used to filter out newly generated sentences that lead to incorrect ThingTalk translations. The idea behind this is that as long as newly generated sentences do not deviate too much from the original, the semantic parser should still be able to correctly translate it. The remaining sentences are then added to the existing original training dataset.
This process can be repeated several times, where in each iteration the new, more enhanced dataset from the previous iteration is used to train a neural semantic parser that can in turn be used as a filter. The idea is that in each iteration the filter becomes more advanced and can translate richer sentences into the correct ThingTalk, thus allowing more paraphrases to pass into the next dataset.
This use of a paraphraser model combined with the paraphrasers used during the Genie Auto-Annotate step vastly improves the quality of the training data.
Conclusion
Even though a completely generated dataset will never be as good as a completely handcrafted one, the procedures described in this blog should provide us with a large dataset (>500k sentences) that is rich enough for a translation model to have comparable performance.
Moreover, since our neural semantic parser is trained with a large pre-trained transformer model it can take advantage of knowledge already present in that model. For instance, the training dataset may have several rows that contain a country, but the total number of countries present in the dataset may only be just five. Because the transformer model already knows about many countries, the neural semantic parser is still able to filter on countries it was not trained on.
Take for example that you would like to know if you have customers from Italy. That country is not present in the Insights database, but still the sentence "Show me all customers from Italy" leads to the following ThingTalk:
@Insights . customer ( ) filter country == null ^^Insights:country ( " italy " ) ;Overall Genie provides us with a fully automatic state-of-the-art process that enables us to build a neural semantic parser in a day. Manual labor would take weeks or months to achieve the same. More information about the procedure and some benchmarks can be found in this paper.
We think we can conclude that Genie is the right framework to achieve our goal of having linguistic interfaces for Thinkwise products.
Future directions
Currently, the prototype only supports filter queries. In future iterations of the prototype, we will add support for tasks, CRUD actions etc.
We were quite impressed with the quality the semantic parser already has, using just the data present in the Thinkwise meta-model and end-product databases and by only applying the automatic enhancements that Genie provides.
However, the Insights model was never developed with linguistic interfaces in mind and adding support for some manual intervention in the process can surely be beneficial. Think of translations specific for the linguistic interface, adding synonyms for property or table names the paraphraser model cannot come up with, or give examples of how class or property names can be used in a sentence.
Of course, you would not want to do that for every table and column in your model, but only for those that do not lead to correct sentences in your training dataset. Luckily, there are methods for analyzing the quality of your training dataset. We would like to incorporate such methods to identify which parts of the Thinkwise meta-model are not correctly translated and could benefit from manual intervention.
The last thing we will be looking at is how to translate the model to other languages. There are two main options for this. First translate all the Genie templates that are used for generating natural language from ThingTalk. As this is quite complicated and labor-intensive, the researchers at Stanford have come up with different automated ways of creating multi-language models. See this paper for more information. However, we will need to investigate whether this automated method leads to models that are of good enough quality or that it is better to translate the Genie templates.