


TL;DR
Thinkwise is ahead of the curve in terms of ridding the world of legacy software, and to keep it that way we have to look ahead. Right now, the Software Factory has the opportunity of becoming one of the first business software development platforms to offer interfaces working with speech or written text (linguistic interfaces). We believe that with state of the art methods, we will to be able to offer high quality linguistic interfaces to all applications made with the Software Factory, without much hassle.
No extra modeling or development will be necessary to get started, though it will be possible to improve baseline systems. These baseline interfaces will be generable from existing applications' models and some examples from their databases. All this can be done while allowing customers to keep full control over their data. From there on out the system can improve based on user interactions. Our goal is to ship, in just a few releases, the ability to generate high quality linguistic interfaces for Thinkwise applications at the press of a button. In the mean time we will be releasing another blog that will get into the nitty gritty of how it all works, along with a demo of what we have so far.
Why do we want to talk to computers?
Thinkwise applications are next to ideal for creating linguistic interfaces, because they are not programmed, but modelled. All information necessary for generating linguistic interfaces in is contained in the model. We can use application models to generate data for fine-tuning large, pre-trained neural networks which perform on par with the best virtual assistants out there (Google Assistant, Siri, Alexa) while allowing us to get these interfaces set up in less than a day.
Having more interfaces is better
Shortcomings of existing media are made apparent by new media filling niches we didn't know existed. The same goes for human-computer interfaces.
Exhibit A
Physical newspapers have seen themselves largely replaced by the world wide web for example. Reasons for this include that we want news when it is in fact new, which the web can deliver better than paper. People's interests also differ, which can be catered to on the web: headlines with links and images for example are more easily skimmed over than entire articles.
Exhibit B
Smartphones have only been available since 2007, but most people already can't imagine a world without them. They have since become the most prevalent device for browsing the internet, forcing web applications to change their interfaces to accommodate them.

Some pros
Linguistic interfaces offer a way of controlling computers with input in the form of natural language. That natural language can take the form of either speech or written text. For the time being linguistic interfaces won't replace keyboard and mouse, let alone screens, but there are plenty benefits to be had by adding them to our repertoire.
One improvement lies in the steepness of the learning curve. Suppose you get a new job and have to do your hour registration. You never worked with the application your new employer uses for this. If the system has a well-built linguistic interface for a language you speak, you would be able to simply say (or type) you want to register your hours.
Additionally, with linguistic interfaces we could operate systems without having to stop whatever else we're doing. Many jobs involve both physical tasks (e.g. lifting) in addition to working at a computer. Dictating instead of typing, and verbally commanding, rather than using a mouse would allow people to switch between working at the computer and doing any other task more fluently.
Why don't we talk to computers yet?
If linguistic interfaces are so amazing, why don't we see them everywhere?
Understanding language is hard
To make linguistic interfaces work, the computer needs to understand language. Understanding language is hard, not in the least because you need common knowledge. The problem is we can recognize common knowledge, but defining it is much harder. Take for instance this toy example:
- I'm on the phone.
- I'm on the bus.
Obviously the first sentence means that you're talking to someone, while the other says you're travelling somewhere. The differences in what we use busses and phones for lead to these sentences meaning something completely different. Representing the meaning of both expressions correctly is thus also contingent on a notion of this difference between phones and busses. In other words, a working understanding of the world is needed to understand language.
But there is an out
The world in which we live shapes our language: what we have words for, and how they are used. So, by closely examining how people use language one should learn what the world is like.
When a neural network is trained to predict the next word in some context, knowledge about the world seeps through into the network. These neural networks have to be huge to be able to hold all this information: hundreds of millions to billions or more parameters making them on the order of gigabytes or more in size. With so many parameters we need to stop them from simply remembering the training data and not really learning anything.
To do this with a fixed task: to predict human-written text, we can really only increase the size of the dataset. Training such neural networks takes hours of computation on expensive, dedicated hardware.
Luckily, big players in the deep learning field have been generously sharing their trained neural networks. Meaning that we can bootstrap solutions to our specific problem with a pre-trained neural network that has already learnt good representations of language. Up-front costs in terms of both time and money are thus greatly reduced.
So these neural networks have some understanding of how language works. We now only need to connect that understanding to the application to interact with it.
State of the art methods for making linguistic interfaces rely on this development and perform better than methods in widespread use today. They let us generate linguistic interfaces using descriptions of APIs, which are included in Thinkwise's application models. Research at Stanford even showed that up-front data collection on user interactions isn't strictly necessary to achieve comparative performance.
How do we go about making a linguistic interface?
Natural language understanding is currently only done by intent classification (in conjunction with slot filling). It forms the basis for toolkits like Rasa, and services like Dialogflow. But we'll argue that this is an outdated approach.
Intent classification?
The method has two instantiations; there is the classic version, which uses developer-defined rules; and the neural version, which uses deep learning. The approach works like this:
- Define intents (and their parameters) based on the application.
- Per intent, come up with utterances that convey that intent.
-
- classic Define regular expressions that match these sentences (and capture the parameters).
- neural Annotate those sentences with the correct intent and its parameters.
-
- neural Train a model to classify sentences as belonging to their corresponding intent and another to identify its parameters (or use a single model to do both).
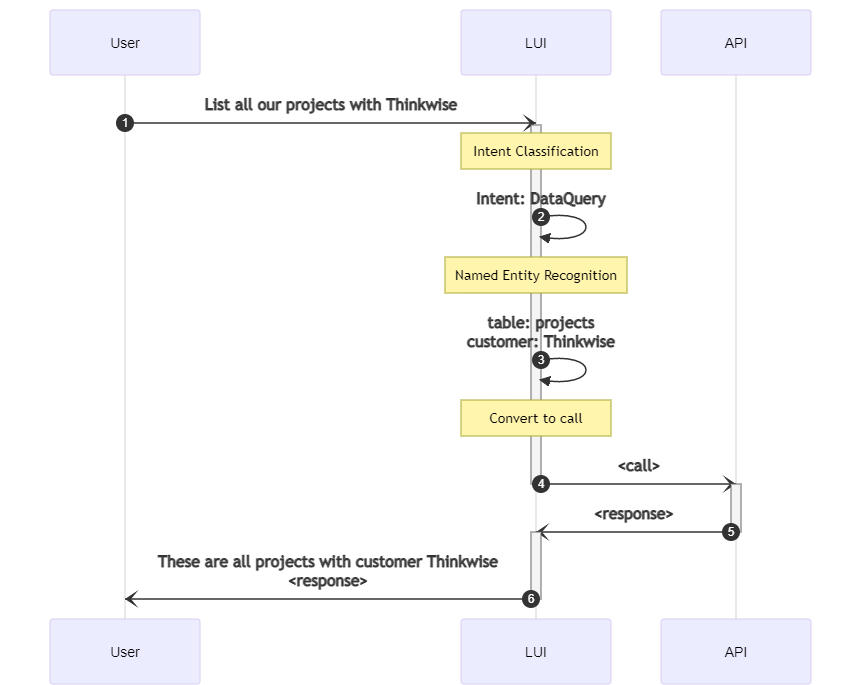
Both classic and neural intent have their own strengths and weaknesses. Deep learning approaches such as neural intent classification are very data hungry, but if that data is available they can handle more varied inputs than rule-based approaches can.
The classic approach has the benefit of being interpretable and reliable. It will never do something that wasn't explicitly programmed in. On the flip side, having to program everything by hand also makes it more labor intensive.
Because of this, classic intent classification is most suited to small applications, or when no user interaction data is available yet. We want to be able to generate a linguistic interface for any reasonable application that can be built with the Thinkwise platform. So our use case is not a small application, it's many large ones, making classic intent classification infeasible.
The neural version is better for most other cases. However, it too will not work without some form of handwork.
For neural intent methods we'd have to annotate large numbers of linguistic user interactions with intents and entities present in our application. We cannot afford to do that for each and every application. Moreover, no user interaction data in the form of language is available.
Intents are too simple
What we want is for the computer to learn a proper relationship between input and output, but with intent classification we attempt to capture something as complex as language with a simple label.
Intents, being simple labels, have no semantic meaning to a neural network whatsoever. Studies have shown that the previously considered to be hard task of image classification: picking a class (dog, airplane, etc.) based on an image, can nowadays be learnt to within 99% accuracy using randomly shuffled labels.
This suggests that the neural network has 'remembered', or hard-coded, the image to prompt a certain label. When this phenomenon occurs unintentionally, that is called over-fitting.
Over-fitting is a problem that occurs whenever a neural network is too complex for the task it is solving. It necessarily means that the network will perform badly on any unseen data. It is therefore likely that a neural network learns nothing useful as long as we train it to associate text with an intent.
Use linguistic structure
Natural language is composed of different parts which can be combined: sentences are made up of at least one independent clause and possibly dependent ones, each with its own internal structure.
Intents do not have any such structure. Compositionality, as this is known, allows one to construct sentences, or longer texts, with arbitrary meaning by composing them from smaller, easier-to-grasp pieces.
Learn more
Take for example the following sentences:
- Generate invoices for all projects finished in the past month.
- Show all projects finished in the past month.
The intentions are for things to be 'shown' and, presumably a task 'generate invoices' to be executed. In both cases a table needs filtering, but classifying these sentences according to their intent ignores this fact.
By ignoring such components and the relationships between them, learning these linguistic structures is not incentivized. Coming back to over-fitting: it isn't that the networks are too complex, the intents are too simple.
Over-fit less
We can tackle the problem of natural language understanding by training a neural network to translate natural language to a formal language. Translation is much harder to learn than associating text with a label because there are many more possible answers.
It is harder to accidentally get the right answer, so over-fitting won't be as much of a problem as with intent classification. For a neural network to translate natural language to a formal language correctly, it must actually have learnt the thing we want it to learn: it must learn compositionality.
The formal language does need to be complex enough. It also needs to have compositionality similar to that of the natural language of choice. But, once we have such a formal language, neural network models trained on this harder task will learn to understand more complex sentences.
Generate training data
Furthermore, because it is a formal language, we can enumerate valid programs: pieces of code that, when run, perform a well-formed API call. Using a description of the formal language, a relatively simple algorithm can be written to translate these programs to natural language.
These translations are somewhat robotic sentences that express the intent to execute the corresponding program. So switching to this new translation task lets us generate training data for our linguistic interface in addition to achieving better natural language understanding.
The entire approach will look like this:
- Define an appropriate programming language.
- Describe application entities, and actions in that language.
- optional Generate sentences with those descriptions, automatically paraphrase, and parse back to find natural ways of expressing entities, actions, and the relationships between them.
- optional Manually correct/augment automatically generated natural language annotations.
- Generate possible programs, using application entities, actions etc.
- Translate those programs to natural language.
- optional (Automatically) paraphrase sentences, to make the training data more natural.
- Train a neural network to translate natural language back to the program.
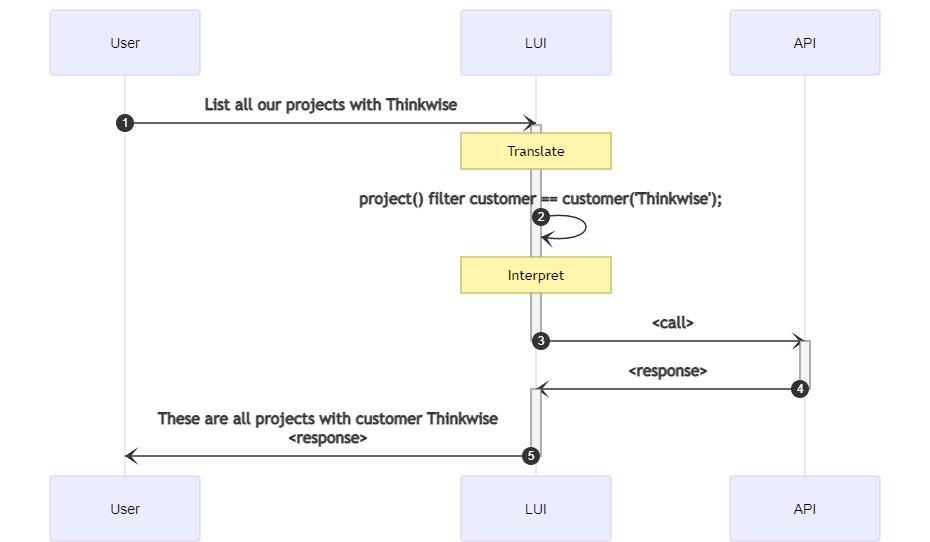
Workings of translation-based linguistic user interfaces (LUI) at runtime. 1. The user gives a command. 2. The command is translated to a program 3. The program is executed, resulting in an API call. 4. A response is returned by the application. 5. The response is returned to the user, along with a message that indicates the machine's interpretation of the command.
Since this approach is put forward as an open source project (Genie by the Stanford Open Virtual Assistant Lab), most of these steps are already done for us. We only need to describe the application entities and actions.
Moreover, describing application entities and actions is exactly what Thinkwise's application models do, so generating a representation the open source project can deal with is relatively simple. As for training the neural network, it is only as hard as training the best ones used in neural intent classification.
Now what?
In the past several months we have put some effort into building a prototype. You can look forward to a second blog post that will detail what we have done so far, and how it all works. Along with the second blog post we will be releasing a demo that will give you a rough idea of what these linguistic interfaces will be able to do.