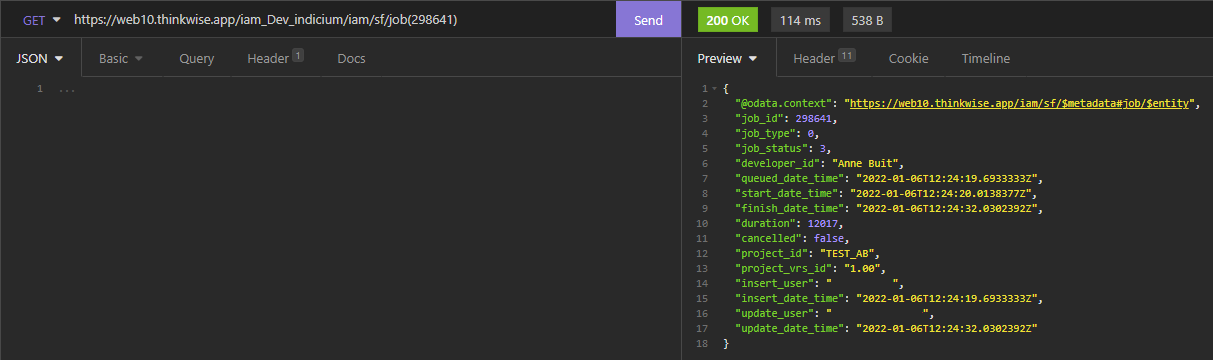
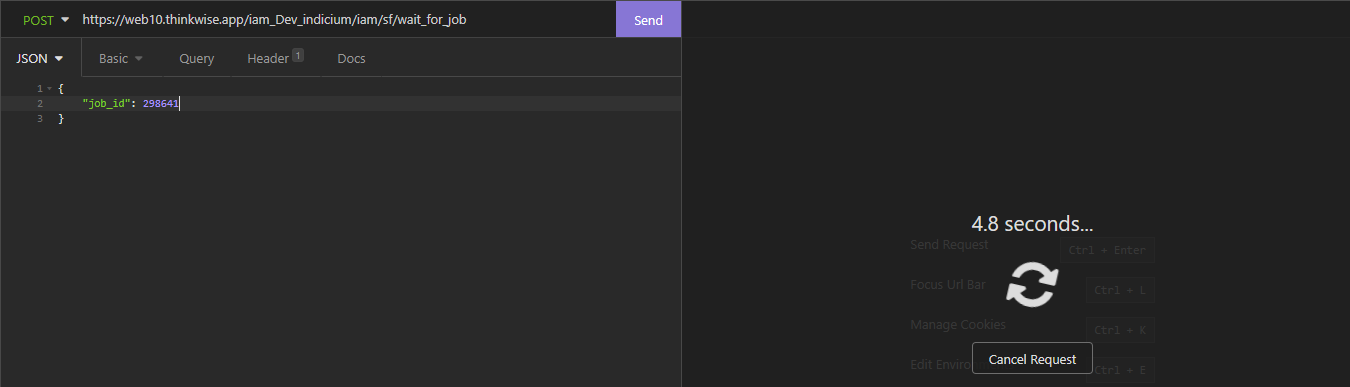
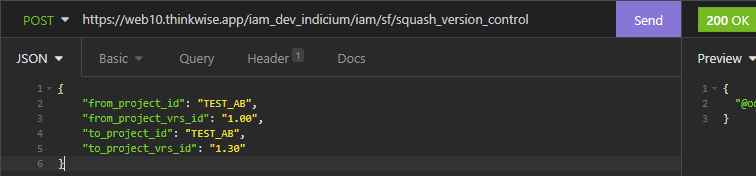
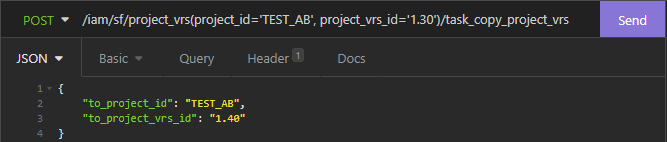
The Thinkwise Platform version 2021.3 has revised the way the Creation screen works, opening up more elegant ways to leverage tooling to automate this process.
The generation screen consists of a number of steps:
- Generate definition
- Validate definition
- Generate source code
- Execute source code
- Run unit tests
This has remained unchanged between versions 2021.2 and 2021.3. However, the way these steps are performed has fundamentally changed.
In the previous version, the steps in the generation screen were bound to a specific client. A developer would start Generate definition and the definition generation would be orchestrated start-to-end by the users client. This has served us well for many years, but there are some drawbacks that we’ve addressed in this release.
The new Creation approach
All ‘jobs’ are no longer performed by a client, but are instead performed by Indicium. This means that generation, validation and such will continue even if the developer closes the screen or even the Software Factory GUI.
Furthermore, all developers will be able to track progress of a job. If a developer starts generating the definition of a project version, a different developer will also see this in their Creation screen.
This behavior extends to the validation- and unit test tabs in various modelers. The validation and unit test screen, that can be opened directly from the the menu, have also been updated.
What has changed for the developer?
To be able to move the responsibility of the Creation process to Indicium, a few things have changed. We’ve also cleaned up some unused features.
Generate definition
Visually, the generate definition step has been updated to show progress at the bottom and initiate the definition generation via a task.
The screen provides you with information about the most recent definition generation job.
Some configuration options for Generate definition have been removed, namely the options to:
- Skip control procedures in development
- Skip deleting generated objects
- Skip copying base projects
- Skip generation itself
When a developer starts definition generation and an error occurs at one of the control procedures, the definition generation will halt. The developer has various options to either skip the control procedure and continue execution or abort the definition generation.
Note that this choice may also be made by a different developer than the developer initiating the definition generation.
Validate definition
A progress bar is shown at the bottom which displays the progress of current validation executions. A validation will receive a question-mark as icon when subject to re-validation and will show a progress-icon when being executed.
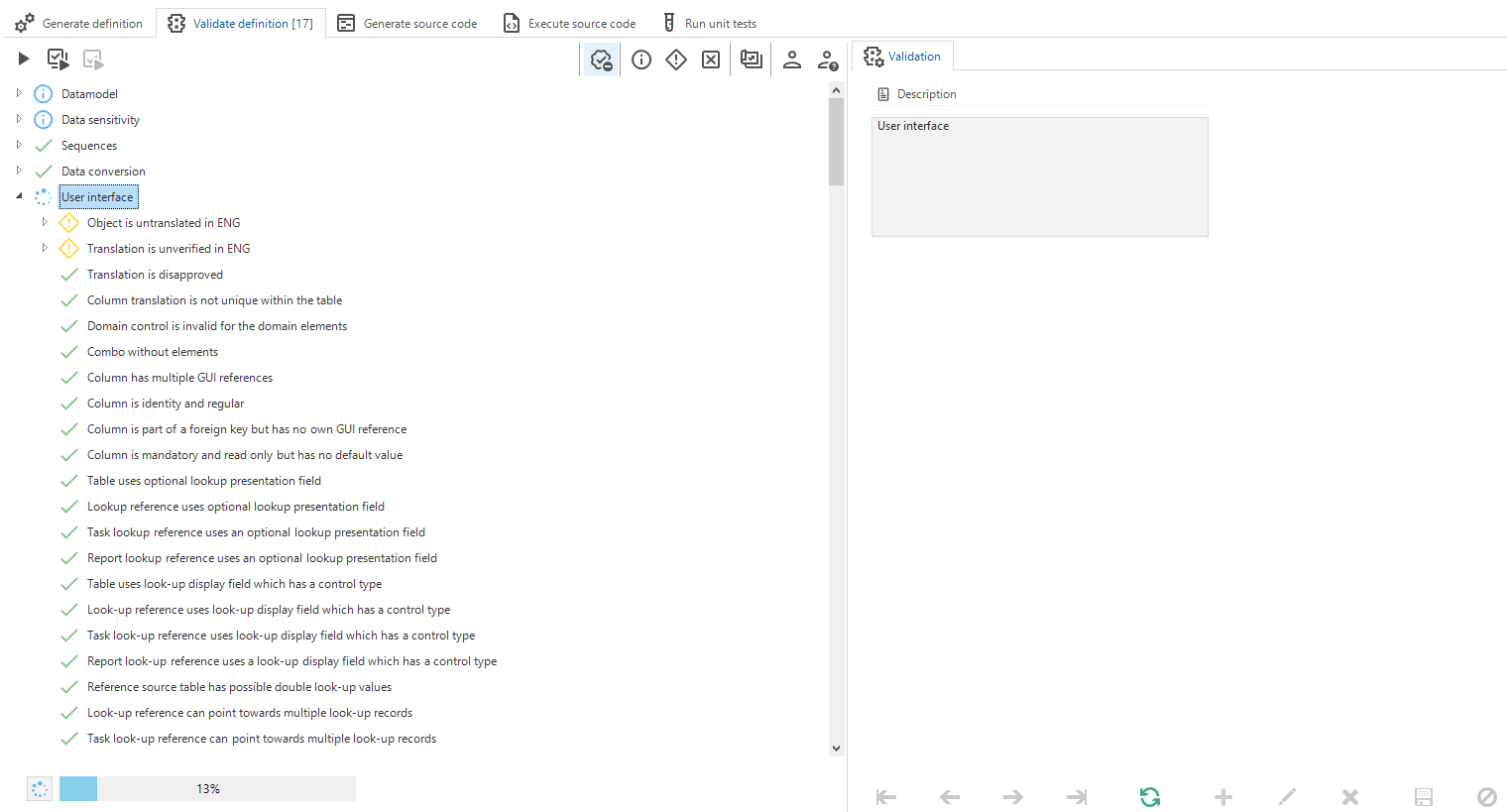
Developers can still choose to perform a full validation or only validate a certain validation group or the selected validation(s).
Note that - unlike other jobs, multiple validation jobs can be active at once for a project version.
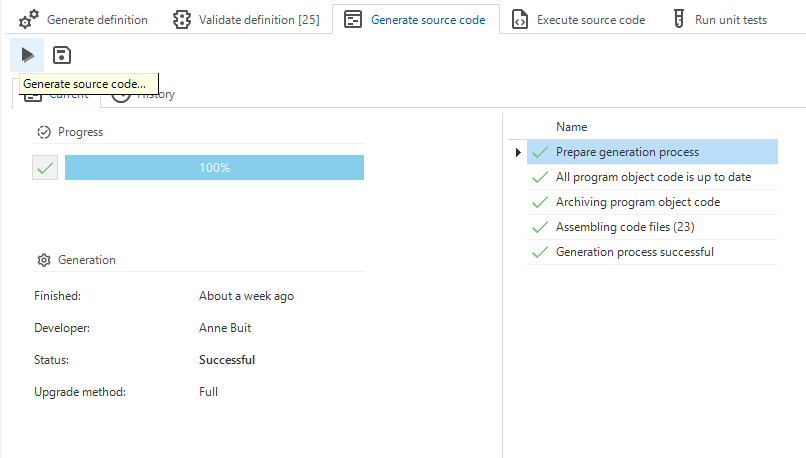
Generate source code
This step has been simplified a bit as there was much functional overlap with the functionality modeler.
Writing all program objects to disk during generate source code is no longer possible. A program object can still be written to disk in the functionality modeler.
Writing code files to disk is no longer a checkbox when starting source code generation. Instead, there is a button that can be used to write all code files to disk.
The generation method Manual is no longer supported. For cherry-pick execution of very specific pieces of logic, use the Functionality modeler or the Code overview screen.
Execute source code
It is no longer possible to execute source code on an arbitrary server and database. The developer must select a runtime configuration. The server and database of the runtime configuration will be used to create or upgrade the database and place the business logic code.
There are two ways to execute source code. In both scenarios, the developer will first be prompted to select a runtime configuration.
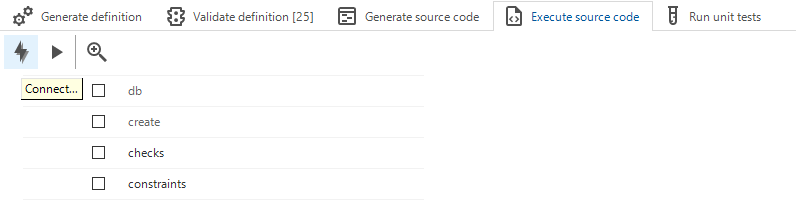
When the Connect option is used, the developer will have the option to change the default selection of code files to execute. The default selection may vary depending on whether or not the database exists, and the current versioning information stored in the database. The developer can also choose to reconnect to a different runtime configuration or cancel code execution at this point.
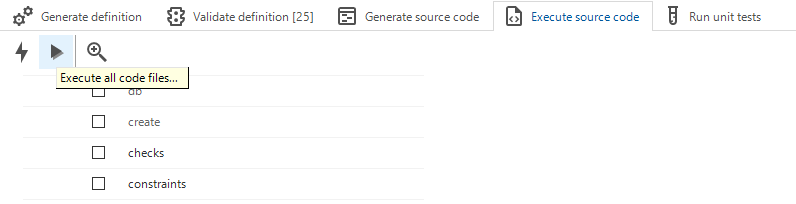
As the name indicates, when Execute all code files is used, no further input will be asked an the code files will be executed directly on the database as provided in the runtime configuration.
If any error occurs during execution of the code files, the developer will be prompted with various options to either continue or abort the code execution.
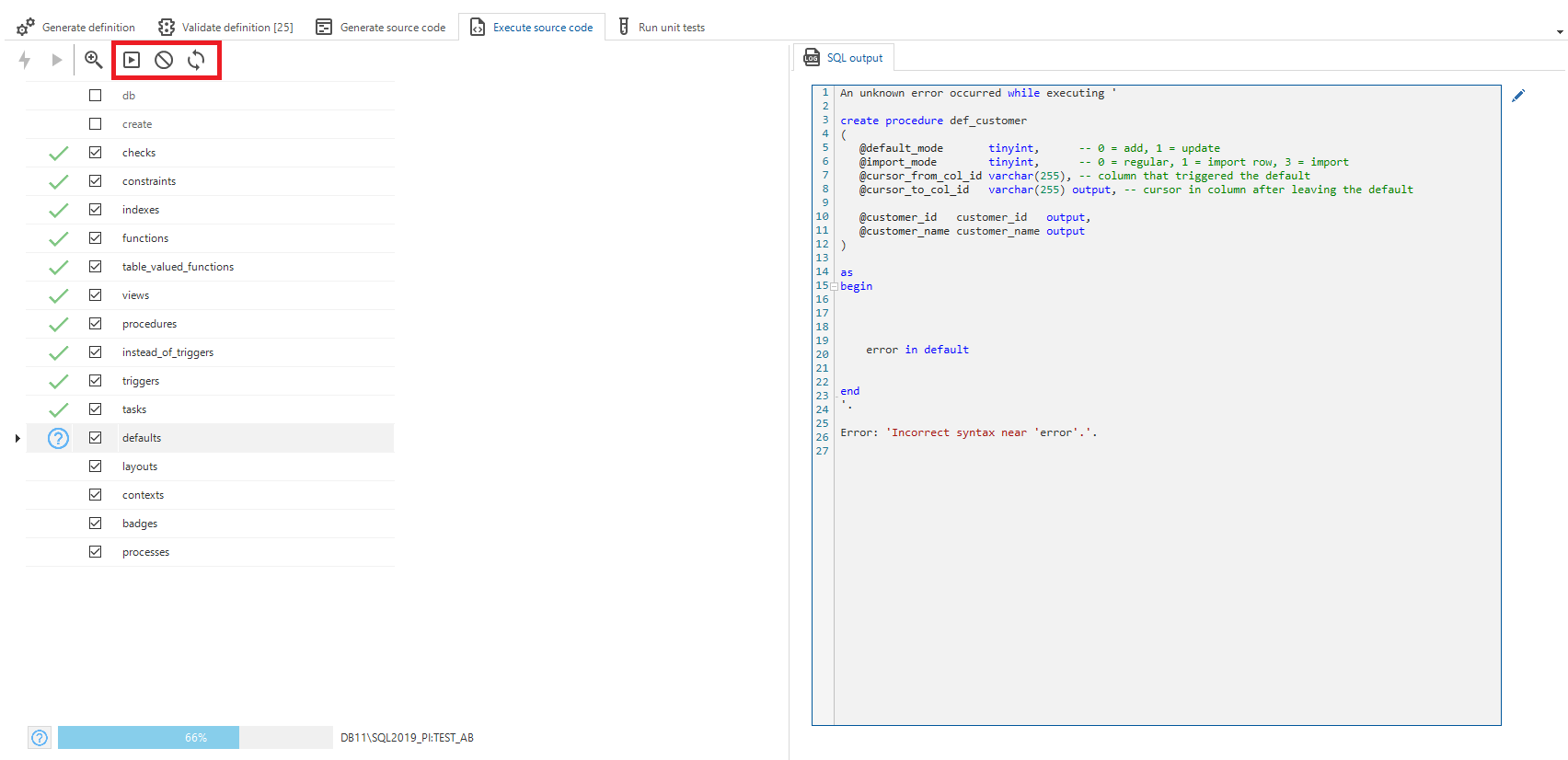
The developer may choose to skip the code file and continue execution with the next code file, to abort execution completely, or to continue with the next statement in the current code file.
Note that this choice may also be made by a different developer than the developer initiating the code execution.
Unit test
Just as with source code execution, it is no longer possible to run unit test on an arbitrary server and database. A runtime configuration must be selected.
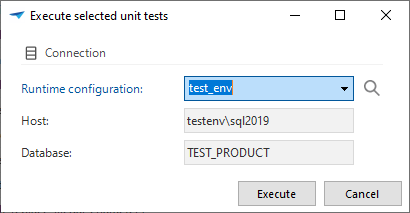
The unit test screen from the menu has also been updated. This screen has been split into a unit test execution tabpage and a maintenance tabpage where unit tests can be created and updated.
Automation
A job may be started by a developer via the UI, but jobs can also be started via the Indicium API. The following API’s may be used to start various Creation steps. The Indicium instance running on the Intelligent Application Manager facilitating the Software Factory must be used for this.
Note that these calls only queue the job and respond with a 200 - OK directly after.
Generate definition
A job to generate definition can be added as following:
POST [indicium]/iam/sf/add_job_to_generate_definition
{
"project_id": "MY_PROJECT",
"project_vrs_id": "1.12",
"error_handling": 1
}I hope the project- and version parameters are self-explanatory. The parameter error_handling allows the caller to configure what happens when a control procedure fails to execute properly during definition generation. The following options are available:
| 0 | Pause and await user input |
| 1 | Skip the control procedure in error and continue |
| 2 | Abort generation |
Validate definition
Starting the validation is pretty straight-forward.
POST [indicium]/iam/sf/add_job_to_validate_all
{
"project_id": "MY_PROJECT",
"project_vrs_id": "1.12"
}Generate source code
Generate source code is accessible via the following API:
POST [indicium]/iam/sf/add_job_to_generate_code
{
"project_id": "MY_PROJECT",
"project_vrs_id": "1.12",
"upgrade_method": 0
}Writing code files to disk is currently not yet possible via the API. The parameter upgrade_method determines the generation method.
| 0 | Smart generation |
| 1 | Full generation |
Source code execution
An execution job can be created as follows:
POST [indicium]/iam/sf/add_job_to_execute_source_code
{
"project_id": "MY_PROJECT",
"project_vrs_id": "1.12",
"runtime_configuration_id": "default"
}The runtime configuration id is used to select the target for the source code execution. Note that this has to be the specific name of the runtime configuration as configured in the Software Factory. An application id or application alias cannot be used.
An error handling option is not available yet but will be added in the future. Source code execution will wait for developer input if an error occurs.
Unit test execution
To execute all unit tests, queue the job as following:
POST [indicium]/iam/sf/add_job_to_test_unit_test
{
"project_id": "MY_PROJECT",
"project_vrs_id": "1.12",
"runtime_configuration_id": "default"
}The body is the same as source code execution. Note that inactive unit tests will not be executed.
Full creation
As an alternative to calling the individual steps for creation, a task is also available to perform all steps for creation.
This task can be found in the first tabpage of the Creation screen and will queue the various steps in this screen in one go.
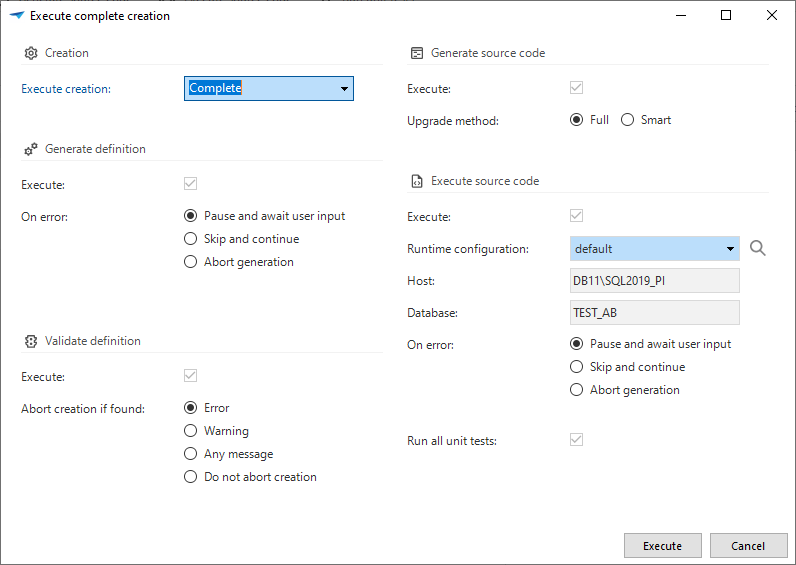
This action can also be called via the API.
POST [indicium]/iam/sf/add_job_to_do_complete_creation
{
"project_id": "MY_PROJECT",
"project_vrs_id": "1.12",
"execute_complete_creation": 0,
"generate_definition": true,
"validate_definition": true,
"generate_source_code": true,
"execute_source_code": true,
"execute_unit_tests": true,
"generate_definition_error_handling": 1,
"validation_result_creation": 3,
"upgrade_method": 0,
"runtime_configuration_id": "default",
"execute_source_code_error_handling": 1
}The execute_complete_creation setting should be set to 0 if manual selection of individual steps is desired. When set to 1, all steps will be executed.
The generate_definition_error_handling and execute_source_code_error_handling values are the same as described earlier:
| 0 | Pause and await user input |
| 1 | Skip the control procedure in error and continue |
| 2 | Abort generation |
The validation_result_creation setting indicates how the validation results should affect the further steps.
| 0 | Abort when there are errors |
| 1 | Abort when there are warnings |
| 2 | Abort on any validation message |
| 3 | Always continue the subsequent creation steps |
The upgrade_method setting is the same as described earlier:
| 0 | Smart generation |
| 1 | Full generation |
Code execution and unit tests execution will both be done on the provided runtime configuration.
More to come - Deployment
This 2021.3 release focuses on automation of the creation screen. The creation screen focuses mostly on your development environment.
For the next release, we will focus on the automation of deployment to IAM environments as well. This includes synchronizing to IAM, writing code files and the combination of both - creating deployment packages via jobs in Indicium.
The packages can be picked up by the Thinkwise Deployment Center to update environments via a wizard or automated via the command-line interface.
Update!
These new features are now available in 2022.1. More information here.