As the tooltip indicates, the "Translating using AI" enrichment uses the fallback language (in our case, English). However, it currently seems impossible to translate an untranslated English or Spanish object using AI, which means the usual "Translate using ID" task must first be performed, followed by the AI translation.
I can understand to some extent that this is a deliberate choice, as you would want to review and approve a manually translated or ID-based object before proceeding with further translations. This approach mitigates the risk that, if the initial translation is flawed, the subsequent translations will also be incorrect.
Do you agree with me that the user interface could still be improved? Currently, the task is executed, and you have to navigate to Enrich model > Run enrichment to see that no update can be performed. A simple improvement could be disabling the AI task if the fallback language lacks a translation.
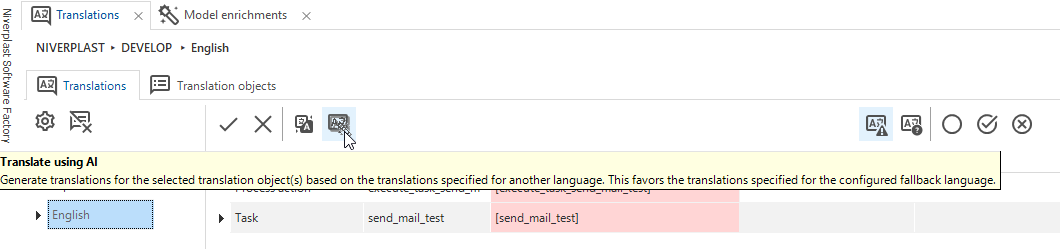
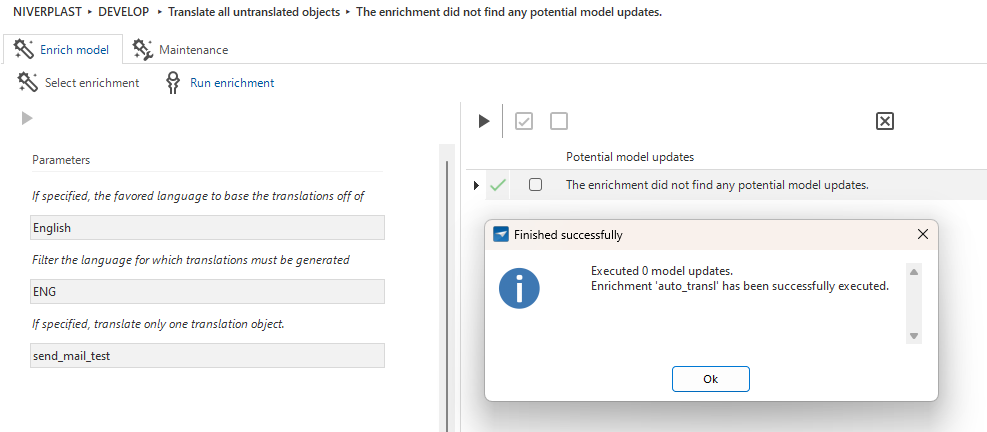
Additionally, I am very curious about the technical handling of the API calls between SF and the OpenAI API. Are the enrichment calls temporarily stored in a (temporary) table within SF before they are actually sent to the API, or how does this process work?