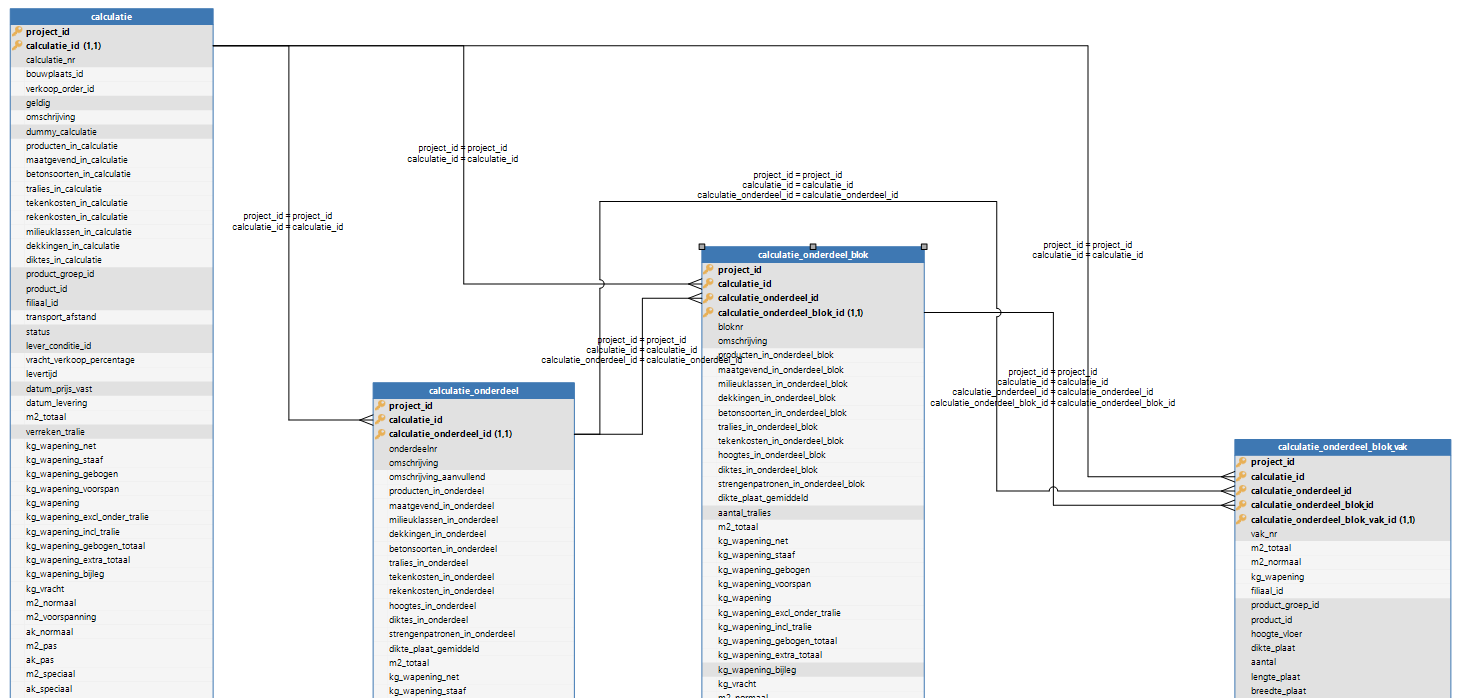
When I was studying the present situation in our system, I came across attached database design. I would never have designed it this way myself, but since I'm relatively new to database design and eager to learn, I wonder what the advantages and disadvantages are of laying out the references and private keys in this way.
A 'calculatie' consists of one of more 'calculatie_onderdeel' which consists of one or more 'calculatie_onderdeel_blok' which consists of one or more 'calculatie_onderdeel_blok_vak'.
When I would have been the one to design this, I would have used one private key per table. E.g. calculatie_id for the first, calculatie_onderdeel_id for the second and so on. Then I would have created PK / FK references on these id fields.
Please see attached picture of the design I'm referring to.
Any thoughts on this, or some background information are welcome.
Best answer by Vincent Doppenberg
Hello Dennis,
I'm not an expert at designing databases myself, but I can at least give a little insight based on how I understand it.
Making the primary key of a child table (such as calculatie_onderdeel) expand upon the primary key of its parent table (calculatie) is often advantageous for the performance of the queries on the child table. I will try to explain why this is the case.
When you have a parent table and a child table, the records in the child table usually don't have a standalone purpose. In practice you will find that you will typically filter the child table on a corresponding record of the parent table. For example, you will often want to query all calculatie_onderdeel records that correspond to a certain calculatie, whereas you will rarely query specific calculatie_onderdeel records outside of any context.
Because of this fact, including the primary key of the parent table in the primary key of the child table is advantageous for the performance, because this will cause it to be part of the clustered index which is automatically created for the primary key. Because the clustered index of the child table is now ordered on the primary of the parent first and then by its own identity value, it is optimized for filters on the primary key of the parent. It will able to resolve these filters with a Clustered Index Seek, rather than a much more expensive Clustered Index Scan.
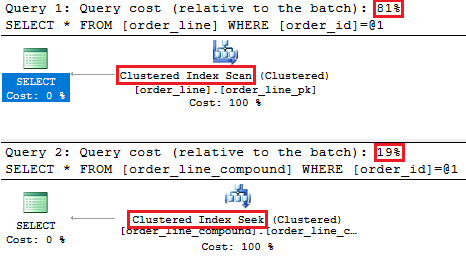
I have created a small sample with order and order_line where I have used both your solution and a solution with compound keys such as shown in your attached design.
When executing both of these select queries:
select *
from order_line
where order_id = 1233select *
from order_line_compound
where order_id = 1233
The execution plans looks like this:
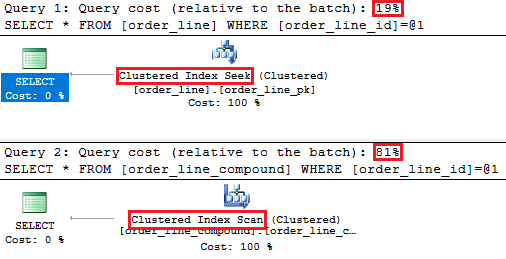
Conversely, when executing both of these select queries:
select *
from order_line
where order_line_id = 1233select *
from order_line_compound
where order_line_id = 1233
The execution plans looks like this:
The first query is just much more common than the second query. It is possible to improve both situations with additional non-clustered indexes, but I'll leave my answer at this for now.
I'm not an expert at designing databases myself, but I can at least give a little insight based on how I understand it.
Making the primary key of a child table (such as calculatie_onderdeel) expand upon the primary key of its parent table (calculatie) is often advantageous for the performance of the queries on the child table. I will try to explain why this is the case.
When you have a parent table and a child table, the records in the child table usually don't have a standalone purpose. In practice you will find that you will typically filter the child table on a corresponding record of the parent table. For example, you will often want to query all calculatie_onderdeel records that correspond to a certain calculatie, whereas you will rarely query specific calculatie_onderdeel records outside of any context.
Because of this fact, including the primary key of the parent table in the primary key of the child table is advantageous for the performance, because this will cause it to be part of the clustered index which is automatically created for the primary key. Because the clustered index of the child table is now ordered on the primary of the parent first and then by its own identity value, it is optimized for filters on the primary key of the parent. It will able to resolve these filters with a Clustered Index Seek, rather than a much more expensive Clustered Index Scan.
I have created a small sample with order and order_line where I have used both your solution and a solution with compound keys such as shown in your attached design.
When executing both of these select queries:
select *
from order_line
where order_id = 1233select *
from order_line_compound
where order_id = 1233
The execution plans looks like this:
Conversely, when executing both of these select queries:
select *
from order_line
where order_line_id = 1233select *
from order_line_compound
where order_line_id = 1233
The execution plans looks like this:
The first query is just much more common than the second query. It is possible to improve both situations with additional non-clustered indexes, but I'll leave my answer at this for now.
To add to my reply above, in case you're not familiar with indexes, consider the following examples. The underlined columns are part of the clustered index.
order_id
order_line_id
...
1
1
...
1
4
...
1
8
...
2
2
...
2
7
...
2
9
...
3
3
...
3
5
...
3
6
...
...
...
...
1999
3279
...
order_line_id
order_id
...
1
1
...
2
2
...
3
3
...
4
1
...
5
3
...
6
3
...
7
2
...
8
1
...
9
2
...
...
...
...
1999
486
...
In which of these two tables is it easier for you to find all order lines corresponding to order 2? In the first example you can stop looking as soon as you encounter the value 3 for order_id. In the second example you will always have to look at every record, because any one of them can belong to order 2. This is the difference between an index seek and an index scan.
Your replies and clear examples shed a different light on the design for me. Thanks for effort to give me some background information on these matters.
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.