


There are various methods of creating history tables, but with SQL server you can allow a history table to be made automatically for a table.
To build a test scenario, let’s first create a table called article.
code:
create table article
(article_number varchar(10) not null
,article_name varchar(100) null
,article_price numeric(9,2) null
,constraint article_pk primary key clustered(article_number asc)
)
In order to create a history table, SQL first needs start_date_time and end_date_time columns on the table which is to be logged.
code:
alter table article
add start_date_time datetime2 generated always as row start hidden not null default '1900-01-01 00:00:00.0000000', --Can be anything, but has to be in the past.
end_date_time datetime2 generated always as row end hidden not null default '9999-12-31 23:59:59.9999999', --The default should be the highest datetime2.
period for system_time(start_date_time,end_date_time);
Note: when using temporal table logging within the SF, the start_date_time and end_date_time should be defined in the column definition of the SF.
The start_date_time and end_date_time columns must be of the datatype datetime2. With the addition of “hidden”, the columns are not shown in select * queries, but only if they are explicitly named (i.e. select start_date_time, end_date_time). The default value of end_date_time must also be stated as the highest value of a datetime2 datatype.
Note: The start_date_time and end_date_time may not be explicitly inserted or updated.
Next, a system_time period needs to be specified.
Once this is created, system_versioning can be turned on using the following command:
code:
alter table article set(system_versioning = on);
SQL server will now generate a temporal history table.
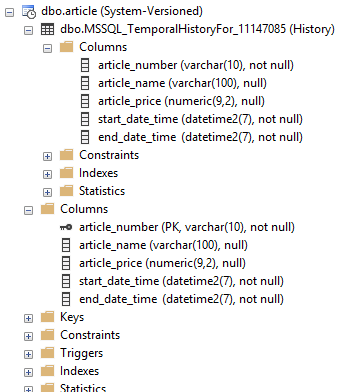
SQL server automatically gives the table a default name, but this can be changed with the following statement:
code:
alter table article set(system_versioning = on(history_table = dbo.article_log));
If the table article_log does not already exist, SQL will create it. Alternatively, you could first create the table article_log and then link this as a log, where the conditions would remain the same.

The article_log will now keep track of changes. Here is an example where we have inserted three articles and then updated one of them.
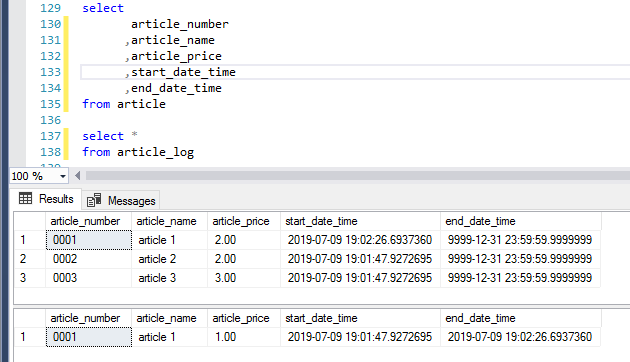
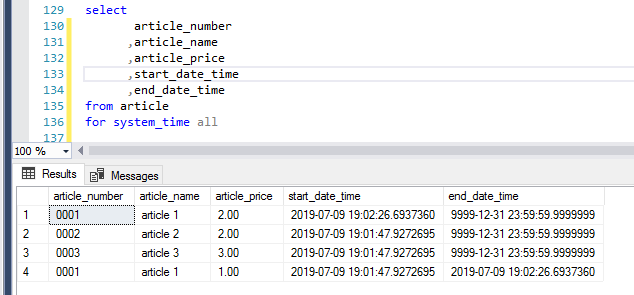
In the example below, the article_price for article 1 is 1.00 at 19:02 but at 19:03 the article_price has been changed to 2.00:
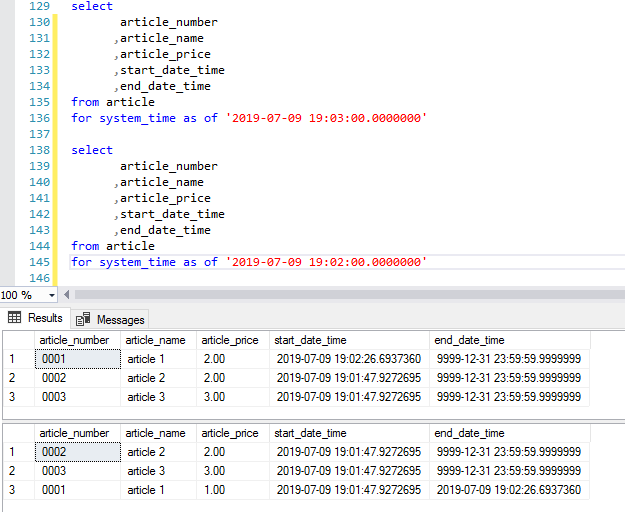
- FROM ... TO ...
- BETWEEN ... AND ...
- CONTAINED IN (..., ...)
- ALL
code:
if exists
(select 1
from sys.tables
where name = 'aticle'
and schema_id = schema_id('dbo')
and temporal_type_desc = 'system_versioned_temporal_table'
)
begin
alter table article set(system_versioning = off);
alter table article drop period for system_time;
end
Note: During the time when system_versioning is turned off, there may be changes to the data which will not be logged. This can be prevented by setting the database to single-user or by running the entire transaction in one execution.
A big question may arise – why should we choose this method? There are various other methods to log tables, and a popular one via the SF is to generate triggers which log changes into separate tables.
Let’s compare these – a table with triggers versus a table with an SQL system-versioning.
We will create a simple trigger for the article table which (without conditions) performs an insert to the log. In most practical cases, these triggers are a lot more extensive in order to first check if something has been changed. However, we will first compare the lightest query (the rowcount and not exists below are generated automatically by the SF).
code:
/* If no rows were modified exit trigger */
if @@rowcount = 0
return
if not exists(select 1 from inserted)
return
-- Do not count affected rows for performance
set nocount on
insert into article_log_tr (article_number
,article_name
,article_price)
select d.article_number
,d.article_name
,d.article_price
from deleted d
We will now perform an update to an article and take a look at the execution plan:
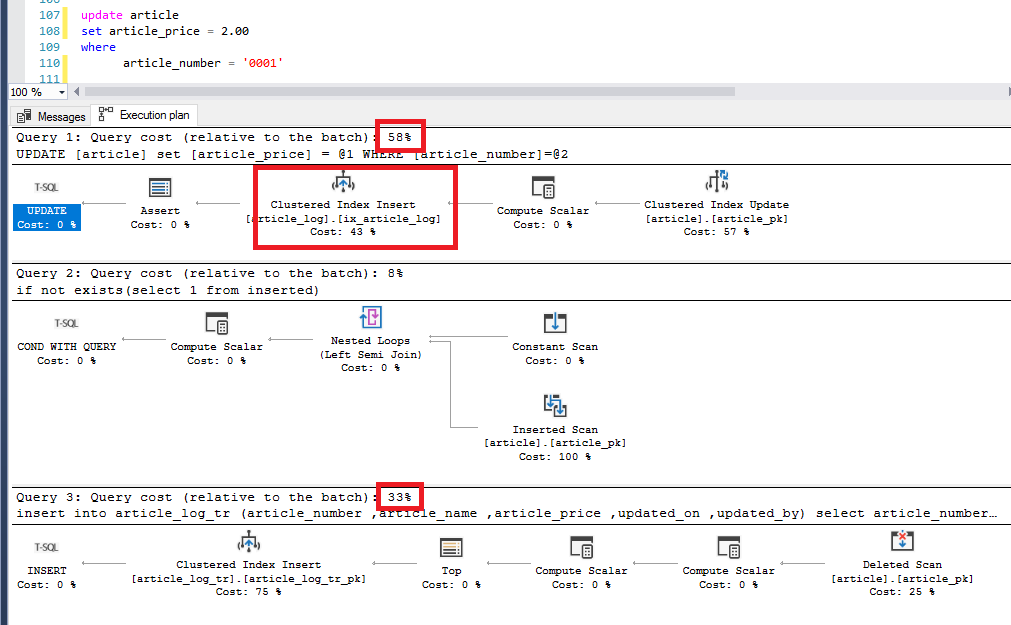
As we can see, the insert alone takes up 58% of the batch, where 48% comes from SQL server.
The simple trigger costs 33% of the batch where the temporal table logging takes 43% of the 58% of the batch (roughly 25% of the total batch)
What happens if we make the trigger a bit more realistic?
code:
insert into article_log_tr (article_number
,article_name
,article_price)
select d.article_number
,d.article_name
,d.article_price
from deleted d
join inserted i
on i.article_number = d.article_number
where (d.article_name <> i.article_name
or d.article_price <> i.article_price)
We see that the query costs have immediately increased:
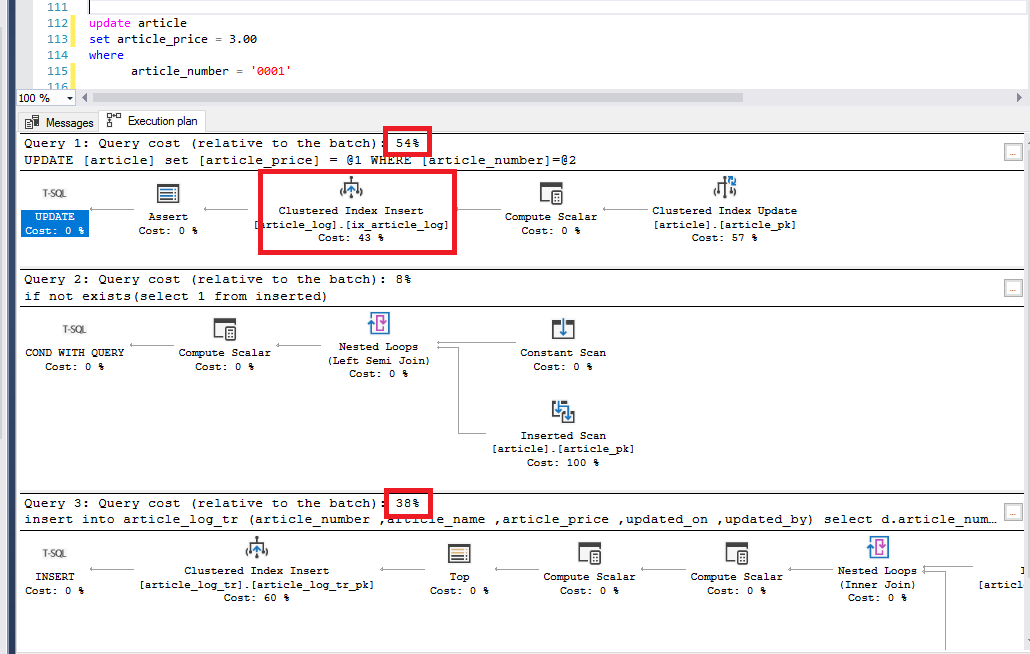
The more realistic trigger costs 38% of the batch where the temporal table logging takes 43% of the 54% of the batch (roughly 23% of the total batch)
In terms of performance, we are already better off. On top of that, this result is with a relatively simple logging trigger, and logging triggers are often a lot more complex and extensive.
However, it’s not always perfect and there are a few drawbacks to the SQL server logs.
For instance, custom codes cannot be added to the temporal tables, it is basically “what you see is what you get”. The user who makes changes is not by default logged. This can however be found by looking at the update users on the current record.
Translations cannot be determined in the log – a reference with translations can of course be established in the SF but then you get the current recorded translation and not the current actual translation updates (unless the source tables have also been logged at the same time). The same applies to domains with elements.
When using a trigger on the article table which updates the article table (i.e. trace columns), then you will get 2 rows in the temporal table logging.
When "ghost updating" a record (i.e. update article set article_price = article_price) you will receive a new record in the temporal table log.
It is not (yet) possible to set this up directly from the SF as there are some custom bits of code needed in the SF core to achieve this (in the base projects).
Here is a step-by-step plan to set up temporal tables as a log within the SF:
- Create 3 DTTP types with the attribute “calculated” so that the columns are included in the upgrade but not in insert and update statements.
- In the table to be logged, the columns start_date_time and end_date_time with the correct DTTP types need to be created.
- A copy of the table to be logged needs to be made but with the domains of the start_date_time and end_date_time changed to the version with dttp_type and the default value removed.
- In the dynamic model, the constraints of the log table must be removed because creating constraints to the log table is not permitted by SQL.
- The log table must not have a primary key. This is not allowed in the SF so the base project needs to be adjusted to be able to accomplish this - it is necessary to discuss this with your Thinkwise contact person, or with our Service & Care team, before attempting this!
- The GUI will display some strange behavior due to it not having a primary key. Therefore it is advised to create a view for the log which would use an identity field as a primary key, which helps the GUI to continue working as expected.
- During an upgrade, the default values of the start_date_time and end_date_time must be filled in the table to be logged. These are not by default filled in by the SF because a column with a dttp_type “calculated” cannot be filled with a default value. This is only applicable if you are adding logging to an existing table. This can be resolved using the dynamic model (generation_order_no: 2000000001).

code:
update v
set v.default_value = case when v.to_col_id = 'system_start_date_time' then '1900-01-01 00:00:00.0000000' else '9999-12-31 23:59:59.9999999' end
,v.generated = 0
from vrs_control_col v
where v.to_project_id = @project_id
and v.to_project_vrs_id = @project_vrs_id
and v.vrs_control_status = 0
and v.from_col_id is null
and v.to_col_id in ('system_end_date_time','system_start_date_time')
and v.to_tab_id not like '%[_]mutation[_]log'
This information is not intended as a fail-safe method for creating logs from SQL server, but rather as information to be able to make a well-founded decision on tables for logging history.


