
On the backlog
Look-up value in cube

- Vanguard

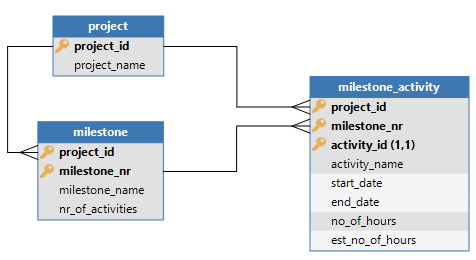
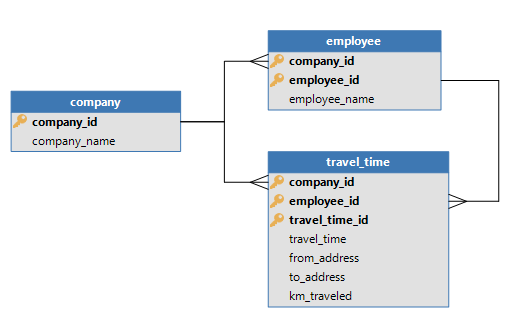
I'd like to see the look-up value of a table in a cube. For example when I want to show the employee, now I have to use employee_name, thats fine. But often I'd like to create a reference between the cube/view and employee, so I have to add employee_id too, now we have two columns what could be one if the cube supported look-up values.















Enter your E-mail address. We'll send you an e-mail with instructions to reset your password.