



Hi,
I have made a system flow that mainly consists of 3 sub flows and a decision + 2 tasks for handling data of a flag value.
This is the diagram in SF:
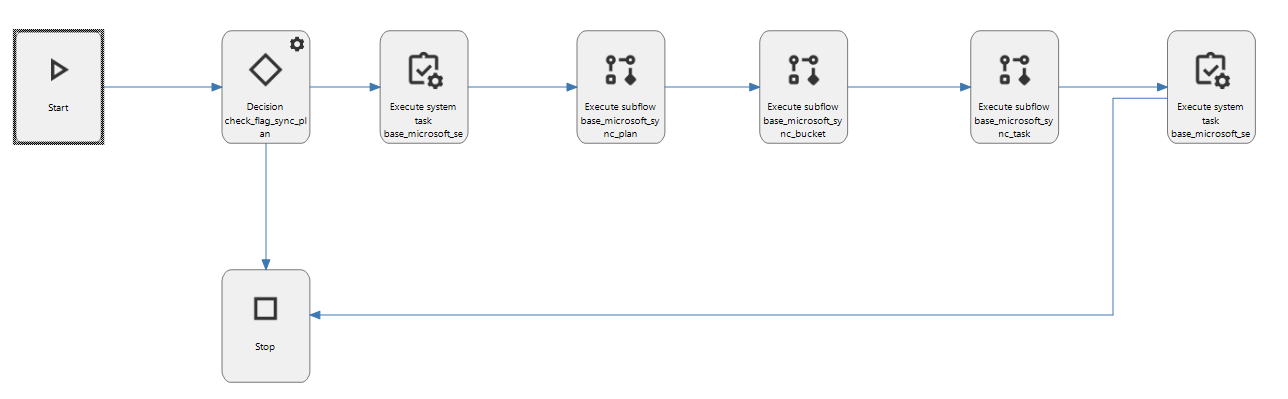
The initial decision checks if the flag value can allow the process to start, otherwise it goes to end.
In the execute subflows, the main process is based on doing repetitive GET calls on ms graph endpoints in order to recieve data for microsoft plans, buckets and tasks. For those processes I use some DTO tables in order to store the fresh data and at end of each subflow, the data from dto table/tables is sync in a transaction with the data from our environment.
When I schaduled the flow to 1 minute for example, everything went smooth and I could see the changes in our environment but things went a little strange when I changed the scaduler to start the process each 5 seconds.
In my oppinion it should check for the flag value and if this is not yet released from the previous run, it should stop the system flow immediately. After some checks in IAM, I saw that it still took the process 8-9 seconds to finish for that case, wich is bizare. And yes, the decision and the flag value does work accordingly since I ve run some manual tests on it.
Made this screen on IAM and the Starting dates (like 1 min each) started actually after a couple of seconds. That results on starting date + end date to increase with 1 minute each 5 seconds
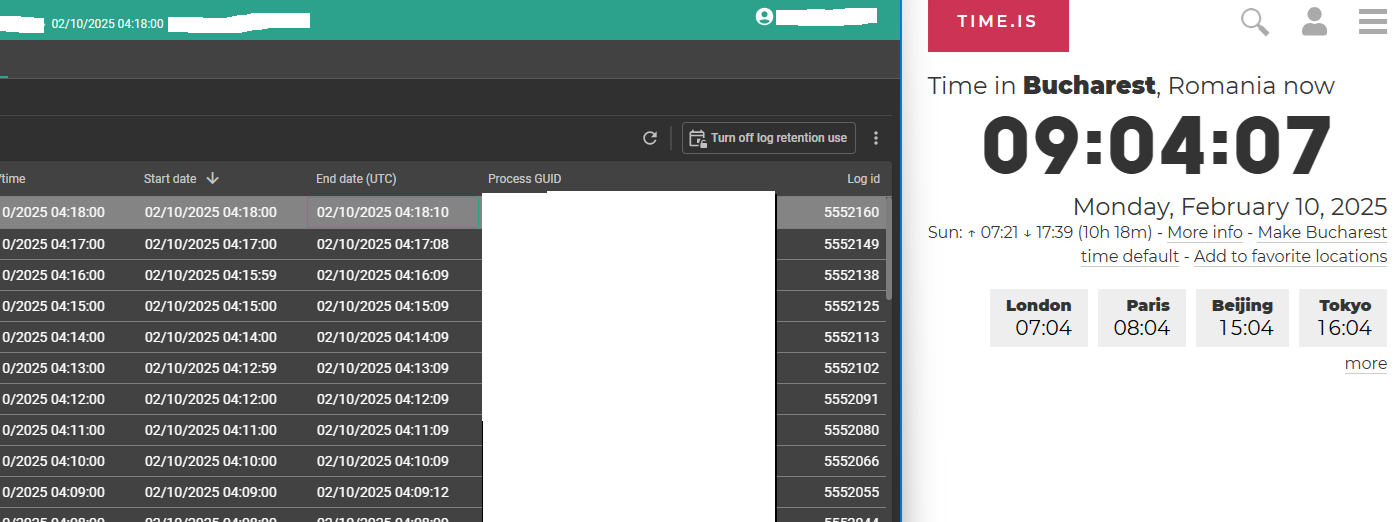
Also, after I schaduled it to try to run each 5 seconds I saw that is messed up with my data. For reference, I use the same DTO table in those 3 subflows and at the beggining of each subflow, the DTO table/tables are cleared so they can be ready for the sync later on. I imagine the data is gone (doing that in a soft delete manner) for some reason that the subflows are being ran in sync and not async even tho they are in a sequence in the process flow (actual system flow).
Thanks,
Paul




