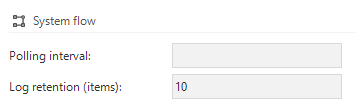
Our entire Thinkwise stack is running on Azure, this means we try to give resources just enough resources for the expected usage.
Recently we started having performance issues on our dev environment, I was able to trace the problem down to the query I included below. It appears to be a clean up for all the process_flow_schedule_logs, this runs every 5 mins and takes on average 40 seconds per run. In this time it caps out our SQL CPU for our plan.
The select query is fast, the delete makes it slow. This is as far as I looked as it's IAM but no matter what I feel like there might be some issue here causing the delete to be this slow.
(@system_flow_log_retention int)with log_items as (
select log_id
from process_flow_schedule_log l
where not exists (select 1
from system_flow_excluded_from_log_clean_up s
where s.project_id = l.project_id
and s.project_vrs_id = l.project_vrs_id
and s.gui_appl_id = l.gui_appl_id
and s.process_flow_id = l.process_flow_id)
and (l.end_date_time is not null or l.abandoned = 1) --Make sure the system flow has finished or abandoned its scheduled run
and l.log_id < (select log_id
from process_flow_schedule_log l2
where l2.project_id = l.project_id
and l2.project_vrs_id = l.project_vrs_id
and l2.gui_appl_id = l.gui_appl_id
and l2.process_flow_id = l.process_flow_id
order by log_id desc
offset @system_flow_log_retention rows --Keep first X amount of rows
fetch first 1 rows only)
)
delete l
from log_items l