The new platform release is here, and what a release it is!
To improve performance and reduce data storage, we completely changed the way version control is handled in the Software Factory.
This really is a major change. It offers a lot of benefits but affects many screens and processes. Read all detailed release notes in the Thinkwise Docs.
In this summary of the release notes, you will read about the key features of the version control and some other highlights.
A major change in version control
Up to the 2022.2 release, version control in the Software Factory was handled by creating a copy of an entire model as a project version. This had a major drawback: since changes make up only a minor percentage of the entire model, all the other unnecessarily copied data made the Software Factory databases grow over time and become slower due to their size.
To solve this problem, we will handle version control from now on by using temporal tables. These tables, also known as system-versioned tables, are a database feature that brings built-in support for providing historical data. It means that only the latest version of every project will be stored, and all old data will be moved to history tables. This way, data modifications will be stored only once. The historical data can be accessed whenever required by requesting them for a specific time in the past.
The use of temporal tables offers great benefits:
- The main benefit is performance improvement by separating the operational data in the Software Factory from the non-operational data. Less operational data needs to be called upon when, for example, copying a project or branching/merging.
- It is no longer needed to store massive amounts of unnecessary data.
- Less risk that a developer accidentally modifies an earlier version of the model because they will always be working on the most recent version.
The decision to use temporal tables has affected quite some screens and processes. We'll name a few here.
'Project' and 'project version' renamed
In the Software Factory, a project used to be similar to a model. However, outside the Software Factory, a project can be much more than just the application or part of an application being built.
Since the Thinkwise platform is based on model-driven software development, we have decided to replace the term Project with Model. For example, the menu item Project overview is now called Model overview. To prevent confusion due to this change, the menu item Full model has been renamed to Model content. This better covers the core of the Software Factory and prevents confusion about how the word 'project' is used in daily life.
Branches and model versions (point in time)
Implementation of temporal tables means it is no longer required to copy all model data into a new project version to save a specific point in time. This means that project versions as we used to know them will cease to exist in the 2023.1 release.
Instead, we will start using branches. These are versions of the same model that can differ from each other. Every model will have at least a MAIN branch and can contain one or more additional branches based on a specific point in time in the past.
Within a branch, you can mark the situation at any point in time (except for the future) as a model version. This is similar to the branching model used in GIT, where branches are effectively a pointer to a snapshot of your changes.
When necessary, you can compare two model versions, for example, between two branches or two points of time within one branch. It is also possible to mark a model version with a name for easy communication.
Branching and merging
The use of branches also changes the branching and merging processes. In the new situation, branching and merging consist of the following steps:
- When you create a new branch, it is no longer a stand-alone project branch but a branch within the model. You can base it on the current point in time, a specific point in time, or select a specific model version. The origin is tagged with the current point in time, and the branch is copied from that point in time.
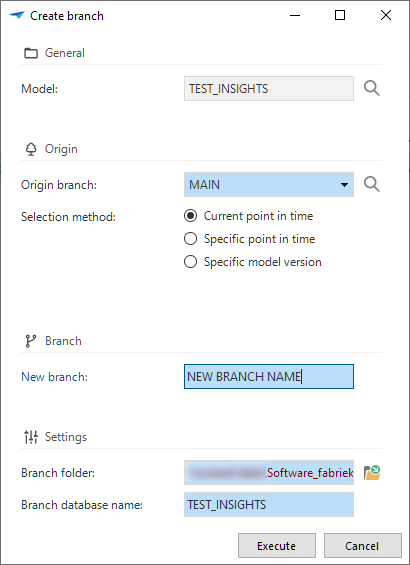
- When you create a merge session, changes are determined by comparing the situation at the origin point in time vs. the current point in time (i.e., the moment when the merge session started).
- When you execute the merge session, only changes from either the source or the origin are executed.
To resolve conflicts, there are now two situations, each with its own resolutions.
The first situation is when an entity has been inserted in both the origin and the branch. In that case, you can choose not only what to do with the conflict actions but also with the dependent actions.
In the other situation, an entity has been deleted or updated in both the origin and the branch or deleted in one and updated in the other branch. For these types of conflicts, you can choose what to do with the conflict action (not the dependent action). For example, when the ‘delete’ action of a table is chosen, the table is no longer available, so column ‘insert’ or ‘update’ actions cannot be executed.
Some other highlights
Domain input constraints
Community idea Universal GUI Windows GUI with Indicium
When creating domains, it was already possible to add some static constraints (minimum and maximum values or lengths, and a pre-defined selection (Elements)). These constraints are applied to the database (stored data will be checked). Data is also checked by the UI and the API. However, if a domain is used in, for example, a view or a task, a static database constraint cannot be applied, though the UI and API will still check the input.
Now, input constraints are available as a feature. This makes the Thinkwise Platform even more low code.
An Input constraint is a more dynamic extension of a domain constraint. It is a simple check on entered data at the domain level, similar to the minimum and maximum values or lengths. Data stored on the database will not be checked, but the UI and API will not accept unallowed input and not process it. Using these constraints, it is no longer necessary to create default or layout procedures to perform these checks.
New process actions
We have added three new process actions:
- Open link - Opens a URL. By default, the link opens in a new tab in the web browser, but you can change that with an input parameter. It can either wait for a user to complete an action inside the opened link or continue the process flow right after opening the link. You can use this, for example, to direct users to an external payment environment in a new tab. After a successful payment, the process flow will continue inside the application.
- Merge PDF - Merges files in alphabetical order, as found in the source folder. The output consists of the merged PDF file and a JSON array with the absolute path of all the merged files.
- Close all documents - Closes all open documents. You can use this action, for example, when switching between different administrations inside your end application. This situation affects all documents, which, therefore, should be closed.
Scheduler formalized
Universal GUI
To extend the configuration of the Scheduler component in the Universal GUI, we have made the scheduler a formal part of the Software Factory.
The Schedulers screen allows more settings for customizing different scheduler views. In the future, this enables setting up different timescales. At the moment, only the previous heuristic timescales can be limitedly configured.
So, the Universal GUI will no longer heuristically configure schedulers but rely on the configured schedulers in the model instead.
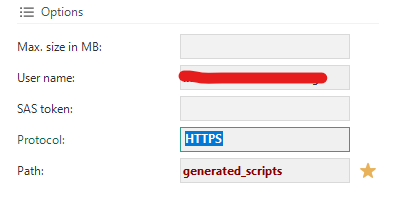
Support for Azure Blob storage and SAS token
We have extended and improved the support for Azure:
- Azure Blob storage is now a supported file storage location. It is possible to authenticate with a managed identity or by specifying the Tenant id, Client id, and the Client secret.
-
Azure files as a storage type now requires a username/SAS (Shared Access Signature) token combination instead of a username/password combination. The SAS token is required for all new Azure file storage configurations. Existing configurations have not been altered. However, if you clear the username/password for an existing configuration, the password field will be hidden, and the SAS token will become mandatory.
Smoke tests
Smoke tests are now available in the Software Factory.
Smoke tests are preliminary tests to reveal simple failures severe enough to, for example, reject an upcoming software release. In the Software Factory, you can use smoke tests to ensure a basic quality level of SQL queries in your application. SQL queries that are not placed on the database as application logic may be malformed. Running smoke tests will discover these malformed queries in advance instead of at runtime.
The smoke tests also detect editable views without RDBMS editing support, ‘instead-of’ triggers, or handlers. They also detect outdated parameterization of logic, and some forms of outdated dependencies for views, triggers, and stored procedure logic on the database.
Questions or suggestions?
Questions or suggestions about the release notes? Let us know in the Thinkwise Community!