

A deadlock usually does not occur until a product is used in a production environment. Even though transactions are rolled back and no real harm is done, the developer will often have to solve the deadlock issues with great haste. This blog post will provide some guidelines on how to find and solve a deadlock.
In this blog post, I’m assuming that the isolation level is the current default isolation level for products – Read Committed.
How deadlocks occur
A deadlock will occur when a transaction (A) is trying to access one or more rows which are in use by another transaction (B). Normally this is not a problem, the transaction (A) will wait until the rows are released. But the transaction (A) will wait indefinitely when the other transaction (B) is waiting for one or more rows locked by transaction (A).
This typically occurs because of triggers. Triggers are always executed in an atomic transaction, even if you do not specify a begin transaction command.
Imagine the following insert-trigger on the table person_import, a staging table that will insert all the imported record in a person-table after doing various checks.
code:
-- Add a person
insert into person
select
i.name,
0
from inserted i
-- Perform another long-running operation
waitfor delay '00:00:02'
-- Mark duplicates
update p
set duplicate = 1
from person p
where exists (
select 1
from person p2
where p2.name = p2.name
and p2.person_id < p.person_id)
A deadlock situation is possible when executing this code parallel from different connections. The inserted person in the first statement will remain locked by the first transaction (A) during then entire trigger. A second statement will also cause a transaction (B) to lock a new record throughout the entire trigger.
When both transactions arrive at the statement where duplicates are marked, the first transaction (A) will want to read the person created by transaction (B) and vice-versa.
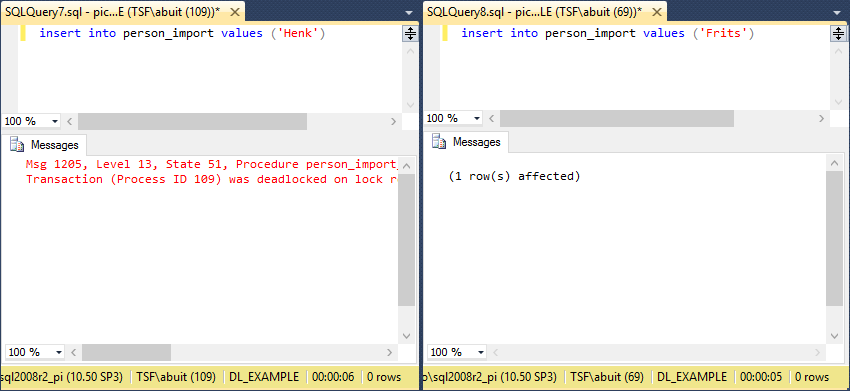
It should be noted that this example also shows why deadlocks are more prevalent when the system is under heavy load. If the statement that causes a 2-second delay is removed, the chances of getting the deadlock are very minimal.
How to find the deadlock
Luckily, SQL Server will detect the deadlock and choose one transaction as the deadlock victim. This transaction will be rolled back, to allow the other transaction to continue. The victim will get a message.
Most deadlocks are not as simple as the deadlock mentioned in the example and can be hard to find. To find a deadlock, it’s best to use the tooling provided by SQL Server.
SQL Server 2012 and above provide Extended Events as a part of SQL Server Management Studio. Extended Events can be used to monitor virtually anything that’s going on in an SQL Server instance, including deadlocks. Extended Events can be found under the Management section of a server. Earlier versions of SQL Server can use the SQL Server Profiler to trace deadlocks.
Create a new session at the Extended Events.
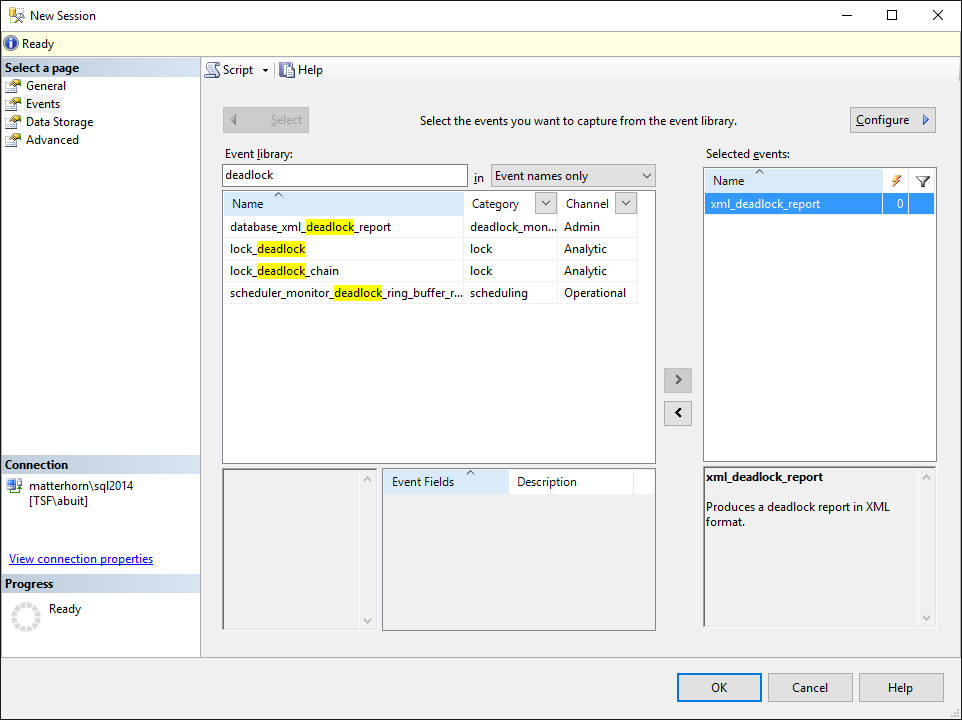
Find the xml_deadlock_report in the event library and move it to the right column, to mark the event to be captured. For more advanced settings, the Configure button can be used to capture extra information or filter on this information. Filtering on a specific user or database name is not uncommon.
Confirm the creation of the session. Using SQL Server Management Studio, it is possible to start and watch the session. When watching live data, the deadlock events will pop up in the Live Data tab and will provide information about the deadlock in the form of a deadlock graph.
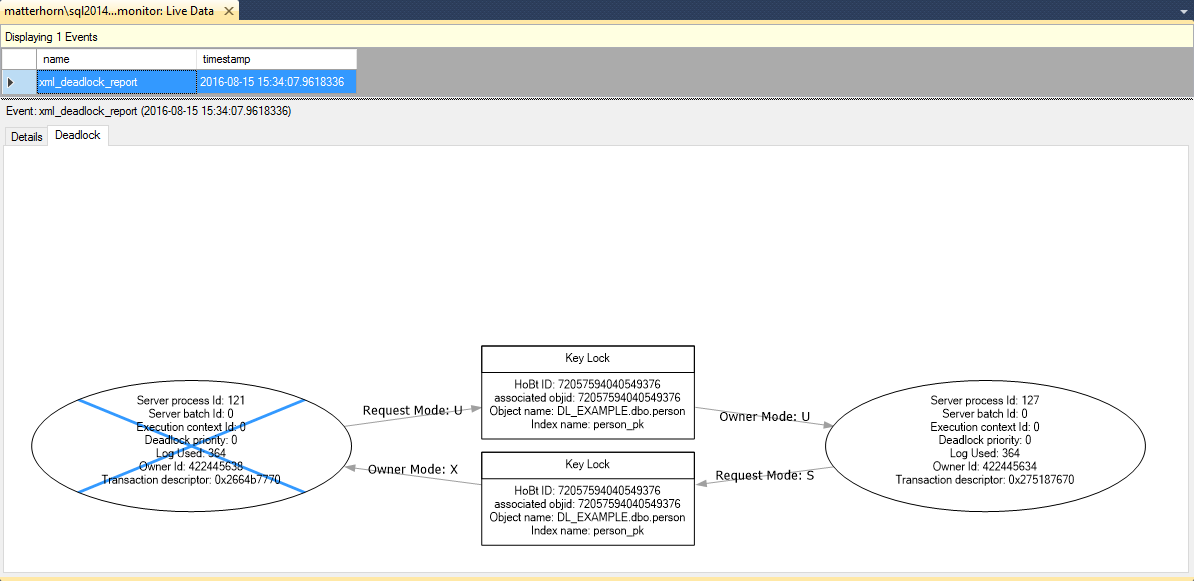
In this deadlock graph, it’s easy to see that process 121 has an exclusive lock on a person record. Process 127 managed to even update a record as duplicate but cant read this inserted record yet. Meanwhile, process 121 is trying to update the record inserted by process 127.
Deadlock graphs are representations of captured XML data of a deadlock. Within this XML data there is a lot more interesting information about the deadlock. For instance, the entire stack of both commands can be seen in the executionstack. If an insert causes a deadlock 3 triggers deep, this can be seen here.
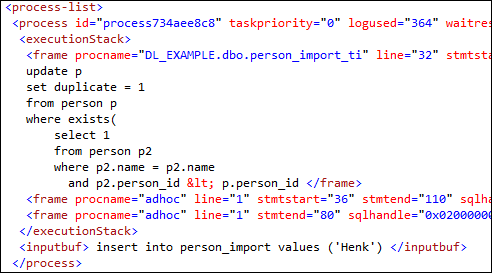
The cause of a deadlock in a TSF application is often found in triggers, since stored procedures are not executed within a transaction unless explicitly specified within the stored procedure body. If the earlier code were to be in a stored procedure it would not cause a deadlock. Unless the stored procedure is performed within a transaction, like being called from a trigger.
How to solve deadlocks
It is not easy to solve a deadlock, but there are some best practices to prevent deadlocks
Always modify objects in the same order
When one trigger updates customer then project, and another trigger updates project then customer, this situation is very deadlock-prone.
Aim for short-running transactions
The longer a transaction runs, the longer objects are locked. This will increase the likelyhood of deadlocks.
Optimize for minimal locking
The fewer locks, the lower the chance of a deadlock. Optimizing indexes is key here. When a query has to search an entire table for records (scans), the chance of the query being held up by a lock is pretty high. When the same query can use an index to quickly find the proper records (seeks), the chances of running into a lock are lower.
Limit queries to their own context
Try not to write triggers that affect other records in the same table, or affect records in another table twice.
For example, determining the next invoice_no on a sales_invoice_ti trigger. This trigger will hold a lock on the inserted sales_invoice record and queries other sales invoices in the same table. This will cause other inserts to deadlock very quickly. The example earlier in this blog also suffers from queries that should be limited further. First the trigger inserts a record, then it queries this entire table at the update statement.
Avoid transactions when not needed
Transactions are a tool to make operations atomic. Everything within a transaction either succeeds or fails. Everything in a trigger either succeeds or fails. The reason stored procedures are not outfitted with a transaction by default is to provide developers with the option of allowing a statement in a batch to fail without affecting the result of the previous statements.
When running an operation that processes a lot of data in different statements, it might be better to not use a transaction but use try-catch statements to maintain structural integrity of the data. This will not only speed up the process, but will also release the locks on data after every statement.
Final notes
A deadlock is not always wrong. When two order lines are added to the same order, it is very hard to prevent deadlocks when the order update-trigger also affects order lines. The issue here might be that two people are trying to edit data in the same context.
Using WITH (NOLOCK) statements within a transaction is very dangerous for the integrity of the application. Having an incorrect order total is worse than having an user re-submit an order line.
Changing the isolation level from READ COMMITTED to READ COMMITED SNAPSHOT can prevent certain deadlocks by using optimistic locking instead of pessimistic locking, at the cost of server resources. More about snapshot isolation can be found here.