The guidelines in this document aim to ensure that Software Factory developers set up high quality data models. High quality means:
- Consistent
- Logical
- Well structured
- Unambiguous
- Data modeling
- Diagrams in the Software Factory
Data modeling
To create well structured data models, a distinction is made between:
- Strong entities
- Weak entities
In the following section Strong and Weak entities form the basis of most of the Guidelines.
General guidelines
- The name must be self-explanatory
- Names singular
- Names lowercase
- No abbreviations
- Unless platform limits are exceeded
- Divide a name into small words (subnames), separated by an underscore.
- sales_order_line
- salesorder_line
- salesorderline
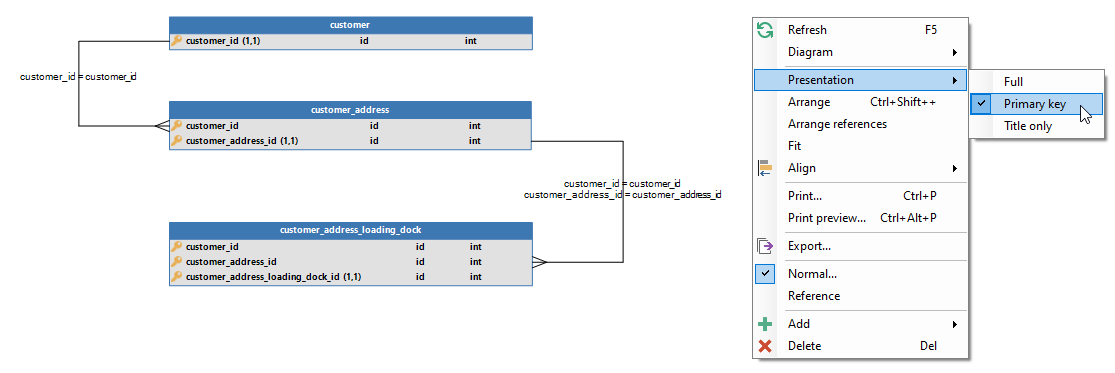
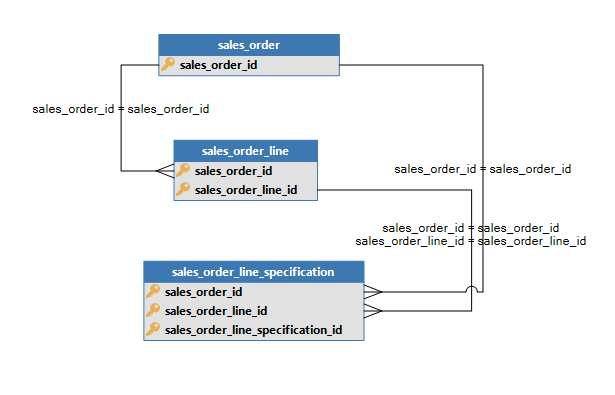
Strong Entity
- Has 1 primary key column
- Does not have foreign key columns in the primary key
- Has more than 1 primary key column
- The primary key columns are ordered from strong to weak
- The last primary key column is not a foreign key, the other primary key columns are
- Has exactly 1 primary column more than his ‘parent’
- Has the name of its ‘parent’ plus an addition
- Target table has his own name. This means that his name is not derived from the ‘parent’ entity
- The number of primary key columns is equal to the ‘parent’
- All primary columns are also foreign keys
- Link tables have all primary key columns from both source tables
- All primary columns are also foreign keys
- Have the name of one table combined with the name of the other table
- (If another name is more suitable, then this table should probably be a Strong or Weak Entity)
- Each foreign column has its own reference
- So if a table has 5 foreign key columns, there must also be 5 references
- A column may be part of multiple references
- The database check must be enabled for every reference
- There are situations where the check is not allowed, for example with a reference to a view
- Last Foreign key column has a new name
- The column does not have a derived name
- The name must be self-explanatory
- Names lowercase
- No meta information in names
- Divide a name into small words (subnames). Place between the words an underscore.
- No abbreviations
- Nr/No
- Id
Primary Keys
- Name Primary key column is table name + _id
- Type of column is preferably an identity with a BIGINT as the data type
- Only primary key columns that are not foreign keys may be an identity column
- The referring foreign key column has the same name as the primary key of the parent table
- If the corresponding reference has an ‘Add’, then this must also be added in front of the column name
- No DTTP in the name
- No length in the name
- No meta information in names
- Primary key columns which are not foreign key columns have the same domain name as the column.
- Use DATETIME2, not DATETIME
- Use NVARCHAR unless the character set needs to be restricted. Then a VARCHAR can be used.
- Identity: use INT or BIGINT
- Use NUMERIC for numbers with digits after the decimal point
- Don’t use CHAR, FLOAT, NCHAR without a specific reason
Example
Software Factory Diagrams
In this section the Guidelines can help you set up Diagrams and Designs.
Guidelines Diagrams
- Name must describe a process
- Foreign key reference: Place parent more on the left side, and child entities more to the right.
- Inheritance: Place parent more to the upper side, child entities more to the bottom.
- Strong-Weak entities: Place parent more to the upper side, child entities more to the bottom.