I'd like to see the look-up value of a table in a cube. For example when I want to show the employee, now I have to use employee_name, thats fine. But often I'd like to create a reference between the cube/view and employee, so I have to add employee_id too, now we have two columns what could be one if the cube supported look-up values.
Did this topic help you find an answer to your question?
I noticed this doesn’t work yet in 2019.2. Is this going to be implemented in the future?
Could we add an option to also sort rows and columns according to the lookup? Sorting alphabetically isn’t always preferred. I tend to resort to appending a number to the values that end up as column names. This even requires an additional column in the table with a sorting number because solutions such as row_number() in an expression don’t work (they result in all 1’s for an entire series).
We’ve evaluated this feature. There are a couple of challenges I’d like to share.
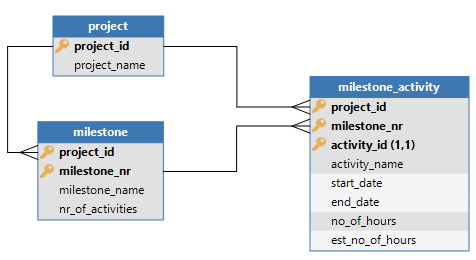
Given the following data structure and data set:
In this scenario, a semantic key is used for milestone (milestone_nr).
The result is that not every unique milestone number will have the same milestone name.
Consider a cube that is set up on milestone activity with the project id and the milestone id as dimensions and the number of hours as value. The resulting cube would use the following dataset:
project_id
milestone_nr
no_of_hours
1
10
500
1
20
300
1
30
100
2
10
13
2
20
44
3
10
9000
3
20
5000
When the data is aggregated per milestone, the resulting cube would look as following:
milestone_nr
no_of_hours
10
9513
20
5344
30
100
These can no longer be translated as look-ups, as the value ‘10’ has multiple translations.
This scenario would favor grouping based on the translation of a look-up dimension, as the semantic key is not meaningful here. This would look as following:
milestone_nr
no_of_hours
Preparation
500
Development
300
Completion
100
Support 1
13
Support 2
44
Research
9000
Construction
5000
However, this would immediately change cubes in an unfortunate way where the semantic key is actually meaningful, and/or situations where the translation is not unique and should always be considered in context of other fields.
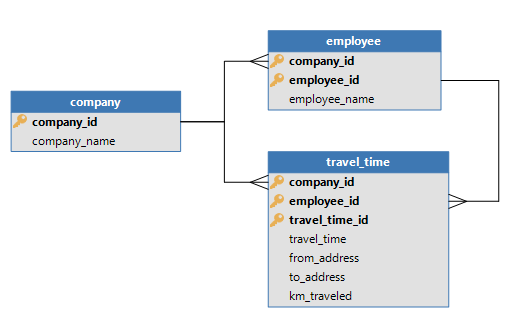
For instance, consider a database which only uses identities. Employee name is unique, but only per company.
When you create a cube of travel time and you do not include the company as a dimension, an employee named ‘John Dough’ in both companies will be aggregated. Even though they have different records and are in fact two different persons.
In this scenario, the end user shouldn’t aggregate based on a translated employee_id, but should always place the employee_id in a group with company_id.
When this rule is enforced, it will be easier for the GUI to translate an employee as the full look-up context is present as dimensions.
I’d love to hear your thoughts on this.
Should we aggregate based on the translation instead of the foreign key value?
Or should we aggregate based on the foreign key values and afterwards translate, provided that the full foreign key is placed as dimensions in the cube?
Dear voters, the above comment by @Anne Buit is a genuine challenge to overcome. We’d really like your input on the matter, after which we can move on to implement this much-requested feature! Would you be so kind to enlighten us with your opinion?
@Anne Buit @Arie V I'm trying to understand here they key point. I think the point here is if a cube should be aware of Primary Key 'constraints'. in both your examples aggregating on milestone_nr and employee_id is erroneous as they are no unique entities. Because the both nr/id are dependent on project/company. So grouping ID 10 in your first example would generate a false value, because the ID is a technical representation that by itself doesn't represent something unique.
In multi-key scenario where a PK column doesn't have a referential constraint, you wouldn't even want to be able to aggregate like that. So if in your last example employee_id had a constraint to an employee table that would guarantee uniqueness, then there is no issue I believe because the lookup value would come from the employee table.
The base point here is that milestone_name and employee_name are multi-key lookups and therefor cannot be referenced by just a part of it's key. If, as said above, there would be an employee table than employee_id would be a feasible lookup as its a unique key in the employee table with hopefully then a lookup value.
--
As you would define the lookup in the cube, it would give you also the grouping information that is mandatory. Eg. you cannot group milestone or employee in your scenarios as a single entity because it doesn't exist as such in your data-scheme. It would only make sense in combination with the other key(s) for that lookup.
Question is if you could incorporate mandatory groupings like this to uphold the constraint that project_id and milestone_nr are together a value you can aggregate. And that project_id is an entity you can aggregate as it would look up to the project table.
I should expect this would work like a normal lookup (display lookup value based on the foreign key). If you don’t want this, you can change the lookup. If you want milestone_name and milestone_nr, add an expression field or create a view as we do now.
I'd like to see the look-up value of a table in a cube. For example when I want to show the employee, now I have to use employee_name, thats fine. But often I'd like to create a reference between the cube/view and employee, so I have to add employee_id too, now we have two columns what could be one if the cube supported look-up values.
Page 1 / 1
I noticed this doesn’t work yet in 2019.2. Is this going to be implemented in the future?
Could we add an option to also sort rows and columns according to the lookup? Sorting alphabetically isn’t always preferred. I tend to resort to appending a number to the values that end up as column names. This even requires an additional column in the table with a sorting number because solutions such as row_number() in an expression don’t work (they result in all 1’s for an entire series).
I support his idea, if this change does not have a significant negative influence on the performance of cubes with a large amount data.
I recently had the same problem: vote = vote + 1
I have the same problem. Is there any word if this is something that is being looked into?
Thanks.
I assumed this was already working in the cube, but unfortunately this community idea shows different.
This would be a great addition and also avoids complexity in cube views.
The following idea has been merged into this idea:
All the votes have been transferred into this idea.
Hi all,
We’ve evaluated this feature. There are a couple of challenges I’d like to share.
Given the following data structure and data set:
In this scenario, a semantic key is used for milestone (milestone_nr).
The result is that not every unique milestone number will have the same milestone name.
Consider a cube that is set up on milestone activity with the project id and the milestone id as dimensions and the number of hours as value. The resulting cube would use the following dataset:
project_id
milestone_nr
no_of_hours
1
10
500
1
20
300
1
30
100
2
10
13
2
20
44
3
10
9000
3
20
5000
When the data is aggregated per milestone, the resulting cube would look as following:
milestone_nr
no_of_hours
10
9513
20
5344
30
100
These can no longer be translated as look-ups, as the value ‘10’ has multiple translations.
This scenario would favor grouping based on the translation of a look-up dimension, as the semantic key is not meaningful here. This would look as following:
milestone_nr
no_of_hours
Preparation
500
Development
300
Completion
100
Support 1
13
Support 2
44
Research
9000
Construction
5000
However, this would immediately change cubes in an unfortunate way where the semantic key is actually meaningful, and/or situations where the translation is not unique and should always be considered in context of other fields.
For instance, consider a database which only uses identities. Employee name is unique, but only per company.
When you create a cube of travel time and you do not include the company as a dimension, an employee named ‘John Dough’ in both companies will be aggregated. Even though they have different records and are in fact two different persons.
In this scenario, the end user shouldn’t aggregate based on a translated employee_id, but should always place the employee_id in a group with company_id.
When this rule is enforced, it will be easier for the GUI to translate an employee as the full look-up context is present as dimensions.
I’d love to hear your thoughts on this.
Should we aggregate based on the translation instead of the foreign key value?
Or should we aggregate based on the foreign key values and afterwards translate, provided that the full foreign key is placed as dimensions in the cube?
Dear voters, the above comment by @Anne Buit is a genuine challenge to overcome. We’d really like your input on the matter, after which we can move on to implement this much-requested feature! Would you be so kind to enlighten us with your opinion?
@Anne Buit @Arie V I'm trying to understand here they key point. I think the point here is if a cube should be aware of Primary Key 'constraints'. in both your examples aggregating on milestone_nr and employee_id is erroneous as they are no unique entities. Because the both nr/id are dependent on project/company. So grouping ID 10 in your first example would generate a false value, because the ID is a technical representation that by itself doesn't represent something unique.
In multi-key scenario where a PK column doesn't have a referential constraint, you wouldn't even want to be able to aggregate like that. So if in your last example employee_id had a constraint to an employee table that would guarantee uniqueness, then there is no issue I believe because the lookup value would come from the employee table.
The base point here is that milestone_name and employee_name are multi-key lookups and therefor cannot be referenced by just a part of it's key. If, as said above, there would be an employee table than employee_id would be a feasible lookup as its a unique key in the employee table with hopefully then a lookup value.
--
As you would define the lookup in the cube, it would give you also the grouping information that is mandatory. Eg. you cannot group milestone or employee in your scenarios as a single entity because it doesn't exist as such in your data-scheme. It would only make sense in combination with the other key(s) for that lookup.
Question is if you could incorporate mandatory groupings like this to uphold the constraint that project_id and milestone_nr are together a value you can aggregate. And that project_id is an entity you can aggregate as it would look up to the project table.
I should expect this would work like a normal lookup (display lookup value based on the foreign key). If you don’t want this, you can change the lookup. If you want milestone_name and milestone_nr, add an expression field or create a view as we do now.
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.