/-This is more of a SQL question-/
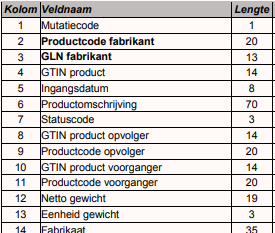
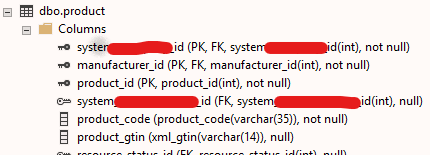
For the project I work on I'm in charge of realizing functionality to import large amounts of Product data (ASCII format / .txt file data). The database I work with is placed in a environment where multiple companies work on the same database. In the application, they only see their own data. For example, if 30 companies use the database and all have a pool of 1 million Products, then the 'Product’ table will have 30 million records in total but will only see their own 1 million products.
The data that I will import consists possibly over a million records and will be inserted into the single ‘Product’ table. What I'm worried about is that inserting 1 million products in one go will take a very long time, so I want to look at possible ways to accelerate this process and making sure that importing big files does not take hours.
I have read about removing indexes, parallel processes and such to speed up the process but I'm not fully convinced it would be the best solution to this particular case.
Community, do you have suggestions for me how I can make this Import functionality as quick as it can be?
Thanks in advance!