
Why do zombies breathe?
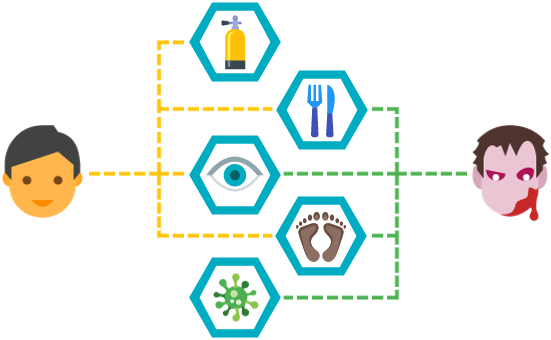
If we want to categorize zombies into one of the following groups: humans, animals, plants or materials, the closest we’d get would be humans. This group includes the basic abilities for humans, such as the most important one: breathing. Categorizing zombies as humans means zombies will own the same basic abilities as humans. Now I don’t know if I am crazy, but why would a zombie need oxygen? As is known, zombies can stay under water for an unlimited amount of time, given that they do not dissolve, and when its head is separated from its body, including lungs, the head will stay alive as long as the brain isn’t damaged. This means the basic breathing ability is useless.Besides the useless ability, zombies can infect other living beings. If we add this ability, it would mean that humans can infect others.
To make a difference between humans and zombies, a new group should be created for zombies, which will be similar to the humans group.
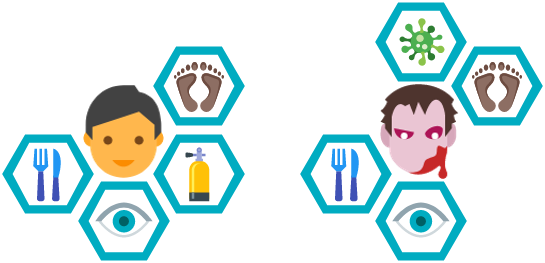
By creating a group similar to humans, most of the basic human abilities, such as walking, eating and seeing, have to be implemented twice. Now, imagine the complexity of the abilities walking, eating and seeing. Implementing, or even explaining or teaching these abilities in detail once is already a difficult job, but now we have to do it twice. Knowing animals and zombie animals can walk, eat and see too, we would have to implement these abilities four times. Implementing and maintaining the same abilities multiple times would be a no-go.
Let’s split the groups into two layers. One layer for groups and one for abilities.

With this double layered structure, abilities are implemented once and shared between groups. Groups can contain a collection of abilities. Now that groups are separated from abilities, we can simply connect the necessary abilities to the two groups.
When new groups are created, it won’t take much effort to provide them with predefined abilities.
What did I just read and why?
This horrifying single layered zombie story can be related to the Intelligent Application Manager (IAM). Currently IAM has only one authorization layer named user group. The authorization is set per application for each user group. When different user groups have a similar set of rights, these rights are arranged separately, which in most cases means extra work and more data.With the upcoming 2017.1 release, we have applied Role-Based Access Control (RBAC) by adding a second authorization layer to IAM named role, which can be related to the ability layer.
Roles
To add an extra authorization layer to IAM, the single layered structure had to be split. One layer to set the rights (role) and one to connect these sets to groups (user group). Therefore, it’ll no longer be possible to explicitly set the rights for a user group.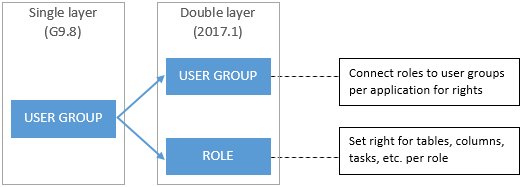
Roles are specific parts of an application on a project version level, which can be interpreted as user tasks, processes or functionalities. For each role, only the necessary rights should be granted. A user group can contain a collection of roles, which grants access to users of this group for all the underlying functionalities.
For example, an application consists of five roles. These roles are divided into 3 different user groups, with role A and C being granted twice.
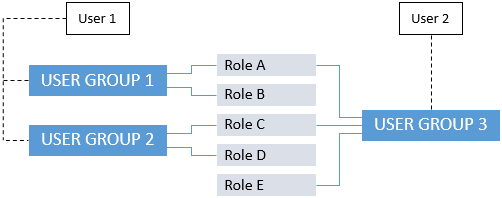
With User 1 belonging to user groups 1 and 2, roles A, B, C and D are granted for this user. User 2 has access to roles A, C and E.
Working with roles
Roles can be found as a group in the menu. In this group, you can find two items: role rights and model rights.
All rights can be set in either one of the two items. The difference between the items is how you approach the rights. In role rights, the user must choose a role first, then set the rights for this role. In model rights, the user can pick a subject and set the rights for different roles per subject.
There are three levels of rights per subject. These types are indicated by color.

A green icon means full rights, yellow means read only rights and, as you might guess, red means no rights. To make it easy to find subjects with a specific permission-type, we’ve added prefilters to the top of each rights screen.
It’s possible to grant all rights to a role, by checking the all rights box in the roles screen. While all rights are granted to a role, the rights indicator becomes a crown and it’s not possible to set individual rights for that role.
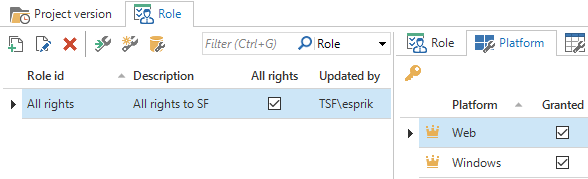
Rights can be granted for several different subjects, such as: Platform, Table, Process, etc. Each subject has its own screen with underlying child subjects as details, e.g. Table has the following details:
- Column
- Tabpage
- Prefilter
- Table task
- Table report
- Cube
- List bar item
- Module item
- Tiles
More about the parent/child rights and dependencies can be read in the Thinkwise 2017.1 IAM Manual.
The rights can be granted either manually, by editing the record, or with the task ‘Assign rights’ — indicated by the key icon. By granting the rights manually, it’s necessary to run through the child and/or parent rights as well. By using the ‘Assign rights’ task, it’s possible to automatically grant rights to the children and/or parents.
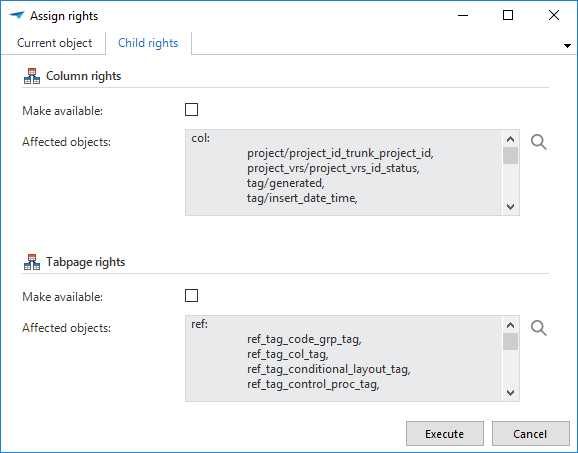
Advantages
Two layersWith the introduction of the extra authorization layer, there’s now a clear difference between functionalities (roles) and groups/departments (user groups). Before, this was only one layer, covering both groups and functionalities.
]No overlap in rights
Because roles are specific parts of an application, each role should only be implemented once. These roles, with the predefined privileges, can be connected to multiple user groups. Before, the rights were granted per user group. When some functionalities were used by multiple groups, those functionalities had to be implemented multiple times. With complex functionalities, granting the same rights several times would be a disaster.
Less data
As for storing data, the roles with all rights are ignored and for the remaining roles only the granted rights are stored. Since roles consist of specific rights and are implemented once, the stored data is rather small, which improves the performance.
Required technical knowledge
Another advantage is the clear bridge between developers and administrators. The developers are the ones building a project (application). Since they know the model and functionalities of their project, setting up roles and granting the necessary rights, which is technical, is easier for them than for IAM administrators. By choosing logical names for roles, the developers can make it easy for administrators to authorize user groups, without having to understand the underlying model or functionality, requiring less technical ability.
No need for model translations
With developers implementing the roles, synchronizing the model translations will be unnecessary, because the developers are already familiar with the technical names of subjects, e.g. table names, column names, etc. These translations were meant for administrators to grant rights to specific subjects without knowing the technical terms. Removing the translations speeds up the synchronization.
How to implement roles
It’s important for developers to analyze the application first, before creating roles. By following a couple of steps, it’ll be easier to determine which roles are needed and what the privileges should be.
The first step should be breaking the application down into roles and determining the scope for each role. The scope contains the subjects, on which rights must be granted, and the permission type for these subjects.
When the scope is clear, the next step will be creating the role and giving it a logical and non-technical name. Administrators should be able to understand the purpose of the role by its name.
The final step for developers will be granting rights to specific subjects for this role.
Example
An application contains the tables employee, department and employee_department. It’s required to have an administrator to arrange departments. This administrator should be allowed to create, update and delete departments, and to add users to departments.
With this information, the necessary rights can be determined. This role must have full rights on the tables department and employee_department, and the underlying child rights. To be able to see a list of employees, this role must also have read only rights on the table employee. As for the child rights, only the required columns, such as id, name, function, etc., should be readable, all others must be hidden.
Considering the scope, a logical name for this role could be ‘Department management’. Examples of unclear or incorrect names are as follows:
- Department manager; this indicates the function of a user, which should be a user group name.
- Employee department management; this name could mean two things. The role either contains the rights for the employee_department table only, or it contains all rights for the tables employee, department and employee_department. In fact, both options are wrong.
- Management; isn’t specific. Managing what?
- Department; isn’t specific. Department what?
How NOT to implement roles
Specifying and creating roles can be a difficult task. It can be done wrong in several different ways, such as the following common mistakes:
- Roles out of scope; specifying the scope incorrectly, by letting roles cover multiple functionalities, might lead to overlap in the rights between roles. This’ll cause extra work and more data.
- Too many rights; when rights or permission-types are not specified correctly, user groups, thus users, can have more (or fewer) privileges than intended.
- Unclear names; when non-logical or technical names are used for roles, IAM administrators may not understand the purpose of the roles. This may lead to confusion, wrong authorization, extra work and many questions, asked by IAM administrators to developers, which could’ve been avoided.
- Roles as groups; this is the case when applications aren’t broken down into roles as functionalities, but into groups. In this case a role will contain all the rights a user group needs and will cover many functionalities. This will, in fact, ignore the extra layer and go back to the single layered structure, which means the user groups will have no actual purpose.