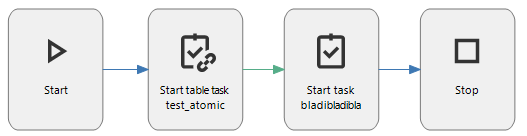
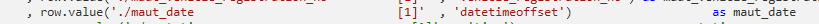When executing a task for a selection of rows, the user interface first executes the context procedure for every single row to check if the user is allowed to execute the task for that row, and then executes the task for each permitted row. This can be quite time consuming, especially for web clients where the progress is also reported back to the client.
To speed up multirow task execution, a new feature has been developed to execute tasks for a selection of rows.
To enable multirow execution for a task:
- Add an XML-typed parameter to the task
- Make sure Popup for each row is switched off
- Set the MultiselectParameterID extended property with the name of the parameter
With multirow execution enabled for a task, when the user interface executes the task, the specified XML parameter is filled with the parameter values for all rows. Even if only one row is selected.
The parameter is only filled when the task is executed. The XML is therefore not visible in the popup or available in the default and layout logic.
Example XML parameter value:
<rows>
<row>
<param1>1</param1>
<param2>a</param2>
</row>
<row>
<param1>3</param1>
<param2>b</param2>
</row>
</rows>Be aware that both the default and the context logic are executed only once and not for every row. The parameter values for all rows are included in the XML, even if the context logic would have disabled the execution of the task for a specific row. The user interface also does not remove duplicate parameter rows when composing the XML, so you'll need to take care of that yourself.
In the task logic, use the XML parameter value instead of the regular parameters, for example:
T-SQL
select distinct
row.value('./param1[1]', 'int'),
row.value('./param2[1]', 'varchar(10)')
from @xml.nodes('/rows/row') as t2(row)
IBM i SQL
select distinct
r.param1,
r.param2
from xmltable ('$xml/rows/row' passing v_xml as "xml"
columns
param1 integer path './param1[1]',
param2 varchar(10) path './param2[1]'
) as r;For information on working with XML data on SQL Server, see this link.
More info on SQL XML programming for IBM i can be found here.









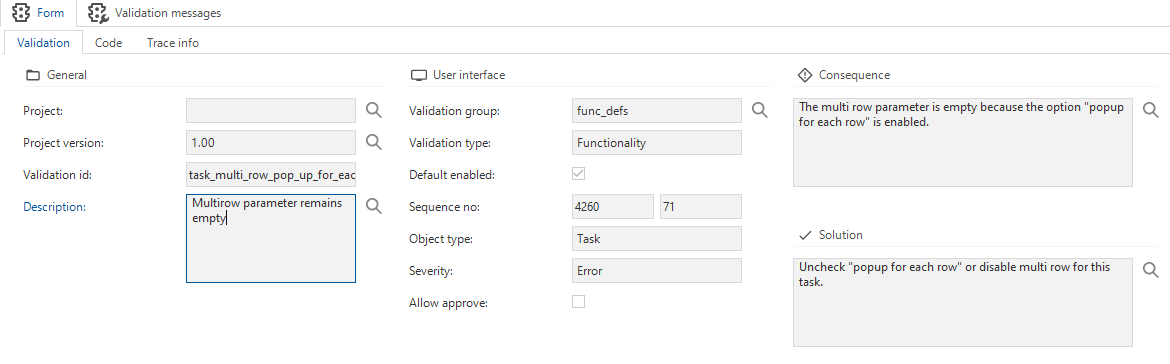

 In the future this feature will be configurable through the metamodel and will probably use
In the future this feature will be configurable through the metamodel and will probably use