
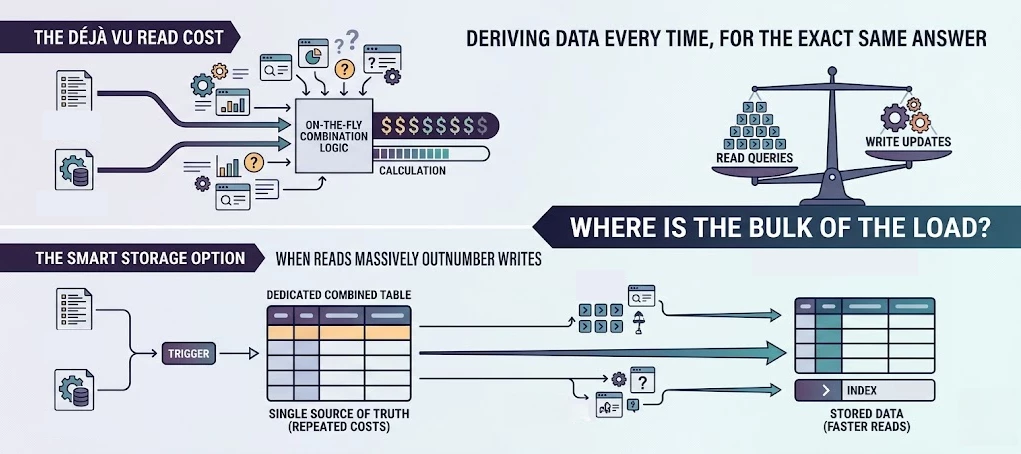

You're in a design session and someone proposes combining master data from two sources on the fly. A function, a view, a subquery. It sounds clean. Always fresh, no redundancy, single source of truth.
But if that combined result gets used in dozens of queries and calculations every single day, while the underlying data barely changes, you're paying a derivation cost thousands of times over for the exact same answer every time.
This article is about one specific scenario where denormalization (storing data in a combined, redundant table) is actually the better choice. It's not a universal rule. It's a trade-off, and I'll tell you exactly when it's worth making.
The scenario
Recently I ran into a situation where master data came from two sources: an external ERP system and an internal list. The proposed solution was an inline TVF that combined these two sources, joined against in queries and calculations throughout the application.
Clean enough on paper. But that combined result would be derived fresh on every query hit, potentially thousands of times a day, while the source tables are updated maybe a handful of times a year.
The data hadn't changed. The work was being done anyway.
The alternative: a combined table with a trigger
Instead of deriving the combined result every time, store it in a dedicated table and keep it up to date with a trigger on both source tables.
The trigger fires on insert, update, and delete on either source. But here's the part that matters: only write when data actually changed. If a process does a fresh load via an API without changing any values, you don't want unnecessary writes rippling through your system.
create trigger trg_source_a_after_change
on dbo.source_table_a
after insert, update, delete
as
begin
set nocount on;
update c
set c.field_from_a = s.field_from_a
,c.last_updated = getutcdate()
from dbo.combined_master_data c
join inserted s
on s.source_a_key = c.source_a_key
where c.field_from_a <> s.field_from_a
endEvery query that needs this combined master data now does a plain seek on a well-indexed table. No derivation, no repeated logic, no unnecessary work. And as a side effect, every query that touches this data becomes simpler to write.
The trade-off
The main objection you'll hear is "but now the data lives in two places." That's fair. There is real maintenance overhead: the trigger needs to stay in sync with the structure of the source tables, and schema changes require a bit more discipline.
My take is that overhead is worth it when reads massively outnumber writes. In this scenario the combined table gets updated rarely, and every other query, potentially thousands per day, gets simpler and faster as a result.
Flip the equation and the answer changes. If the source data changes constantly, the trigger fires constantly, and you've just moved your problem rather than solved it. In that case, derive on the fly.
When does this pattern make sense?
The core question is: where is the bulk of the load?
A combined table makes sense when source data changes rarely (scheduled imports, manual updates, infrequent API syncs) and the combined data is read heavily across many queries. It also helps when query simplicity matters. A plain table is easier for the whole team to reason about.
Stick with deriving on the fly when source data changes frequently, or when the combination logic is too dynamic to capture in a static structure.