When executing a task for a selection of rows, the user interface first executes the context procedure for every single row to check if the user is allowed to execute the task for that row, and then executes the task for each permitted row. This can be quite time consuming, especially for web clients where the progress is also reported back to the client.
To speed up multirow task execution, a new feature has been developed to execute tasks for a selection of rows.
To enable multirow execution for a task:
Add an XML-typed parameter to the task
Make sure Popup for each row is switched off
Set the MultiselectParameterID extended property with the name of the parameter
With multirow execution enabled for a task, when the user interface executes the task, the specified XML parameter is filled with the parameter values for all rows. Even if only one row is selected.
The parameter is only filled when the task is executed. The XML is therefore not visible in the popup or available in the default and layout logic.
Example XML parameter value:
1<rows>
2<row>
3<param1>1</param1>
4<param2>a</param2>
5</row>
6<row>
7<param1>3</param1>
8<param2>b</param2>
9</row>
10</rows>
Be aware that both the default and the context logic are executed only once and not for every row. The parameter values for all rows are included in the XML, even if the context logic would have disabled the execution of the task for a specific row. The user interface also does not remove duplicate parameter rows when composing the XML, so you'll need to take care of that yourself.
In the task logic, use the XML parameter value instead of the regular parameters, for example:
T-SQL
1selectdistinct
2 row.value('./param1[1]', 'int'),
3 row.value('./param2[1]', 'varchar(10)')
4from@xml.nodes('/rows/row') as t2(row)
IBM i SQL
1selectdistinct
2 r.param1,
3 r.param2
4from xmltable ('$xml/rows/row' passing v_xml as "xml"
5 columns
6 param1 integer path './param1[1]',
7 param2 varchar(10) path './param2[1]'
8 ) as r;
For information on working with XML data on SQL Server, see this link. More info on SQL XML programming for IBM i can be found here.
Did this topic help you find an answer to your question?
This feature works very well in conjunction with drag-drop. When you drag multiple rows, you can have a multirow-task execute once with all the dragged rows.
Sounds great. But I can't quite see yet whether this would solve our issue where the process in question contains a http connector. The api we're talking to, only allows a single item to be requested every time. Which means the http connector needs to be ran for every item in the selection, which (if I read correctly) is still not possible.
A possible solution would be to create a process flow in which you recursively store the values of the first row in process flow parameters, delete the row from the XML, and then call the HTTP connector using these parameters.
The SQL code for the task or process procedure to assign the parameters would look something like this:
code:
-- Store the values of the first row select @param1 = row.value('./param1[1]', 'int'), @param2 = row.value('./param2[1]', 'varchar(10)') from @xml_input.nodes('/rows/row[1]') as t2(row)
-- Delete the first row set @xml_input.modify('delete /rows/row[1]')
The HTTP connector should be called while the parameters have a value.
Also make sure you use a different name for the XML input parameter of the task than the MultiselectParameterID.
I don't think looping in processflows ever even crossed my mind. This could be a very nice solution.
One thing though, I would personally prefer keeping a pointer (int) to the current row, this would keep the input intact.
I had to fiddle around a bit, but here's an example of using a pointer:
declare @pointer int = 1 while @pointer < 3 begin select row.value('(./param1[1])', 'int') , row.value('(./param2[1])', 'varchar(10)') from @xml.nodes('(/rows/row[sql:variable("@pointer")])') as t2(row)
I'm trying something similar with the copy file process action to copy a batch of files by obtaining "from file" and "to file" values from a select query. I put all those rows in a table variable and then loop through these rows one by one. But this is the part that eludes me:
The HTTP connector should be called while the parameters have a value.
What happens now is that the loop finishes and ends up outputing a single set of null values. How can I insert a sql "while" loop into a process flow so that it outputs parameters set by set into the process variables?
Reports currently don't support this. We should think about this in a design and investigate whether report implementations are able to process these kind of structured data.
I'd suggest to park this question in a separate post/idea to think about alternatives and to investigate the need for this.
In the future this feature will be configurable through the metamodel and will probably usetable valued parameters instead of XML. We'll be able to automatically upgrade the model, but you'll need to change the code yourself!
Gradually our codebase gets cluttered more and more with your originally suggested solution. Can you get us an update on when you expect the future will arrive on this matter?
@Ricky This is on our backlog, but we have not yet planned a date for this.
It is, however, trivial to locate and rewrite the select (and delete) from the XML to use a table valued parameter. And from a functional point of view, it doesn't make any difference.
In the future this feature will be configurable through the metamodel and will probably usetable valued parameters instead of XML. We'll be able to automatically upgrade the model, but you'll need to change the code yourself!
Gradually our codebase gets cluttered more and more with your originally suggested solution. Can you get us an update on when you expect the future will arrive on this matter?
What we've currently have done is having everywhere the same structure of creating a temporary table, which should be replaceable with the actual solution. We’re everywhere using @multi_row as input and @record as actual table used.
On each template we apply it (almost all tasks), we do something like this:
1declare@recordtable (project_id id not null
2 , part_id id not null)
3
4insert into@record (project_id
5 , part_id)
6select x.value('(project_id)[1]', 'id')
7 , x.value('(part_id)[1]', 'id')
8from@multi_row.nodes('rows/row') as t(x)
I hope for us that we by doing so we only need to remove the code above and can use the @records table.
Jasperwrote:
@Ricky This is on our backlog, but we have not yet planned a date for this.
It is, however, trivial to locate and rewrite the select (and delete) from the XML to use a table valued parameter. And from a functional point of view, it doesn't make any difference.
And how to deal with unit tests on multi rows? Currently I have a long input string (<rows><row><item>1</item></row><row><item>2</item></row></rows>), but that should be converted to some kind of other data structure allowing multiple rows at once? That is less trivial than find and replace?
@Ricky This is on our backlog, but we have not yet planned a date for this.
It is, however, trivial to locate and rewrite the select (and delete) from the XML to use a table valued parameter. And from a functional point of view, it doesn't make any difference.
Hi @Jasper , can you tell a bit more about the table-valued parameters in general what the plans are? And in what period of time? As I can't find it in the ‘ideas’ backlog.
I assume the multi row solution will be replaced by that, but I think I have another case for which table valued parameters could be useful. But I'm not sure it's part of the same, or something new.
It could be useful when you could design them as ‘Domain’, so it can be used in tasks, subroutines and process flows. We currently use a lot of XML passing data in process flows, but handling XML is pretty heavy for SQL Server. It also could decrease our code base as it's no longer necessary to apply transformations from a table variable, to XML, and back from XML to a table variable.
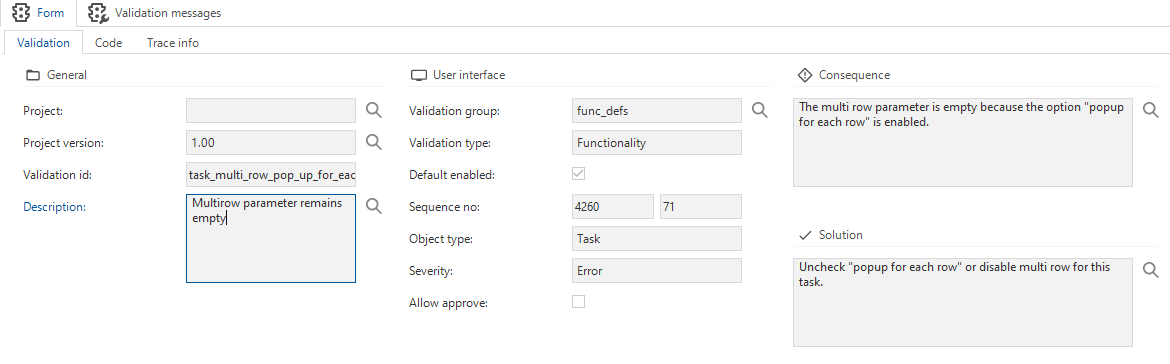
I've created a custom validation to prevent having “Popup for each row” checked while using the multi row feature (which will result in a null value). For those who are interested;
I have created a dynamic control_procedure which automatically generates a @xml_table for each task that has a parameter which is the same as the property_value of MultiselectParameterID.
The goal of this procedure is that we don't have to retrieve the XML manually for all the XML variables and we have the same xml_table for each task procedure, also when we add a new parameter to the table task, this will be added automatically. This way you can use the table @xml_table in the template code for the task, instead of reading out the XML parameter every time you need some data.
Very unfortunate that the multiselect parameter remains empty in default procedures. Is there a specific reason for that? And can we expect this to become available in the future?
I understand it can be complex, but just having the initial values of table parameters available in the multiselect parameter of the default procedure would help a lot to make multiselect tasks even more powerful.
Very unfortunate that the multiselect parameter remains empty in default procedures. Is there a specific reason for that? And can we expect this to become available in the future?
I understand it can be complex, but just having the initial values of table parameters available in the multiselect parameter of the default procedure would help a lot to make multiselect tasks even more powerful.
Hi Harm,
I would imagine that it remains empty because the default is executed per row and not per set.
What is the usecase in which you need the xml parameter in the default?
The default values I wish to set in my task depend on field values of all selected rows and I also like to inform the user about the affected rows before he/she executes the task.
The default values I wish to set in my task depend on field values of all selected rows and I also like to inform the user about the affected rows before he/she executes the task.
Setting the default value would be as easy as in the execution of the task right? Because the default value is not visible for the user anyway there.
And I think you could use a procesflow for this. Execute multi row task → show message → yes → execute task → no → abort
No, this is not what I want. Using a process flow is not desirable, because it will not give the desired result.
I need to now row data of all selected rows to set my task parameters. This to inform the end user better before he/she executes the task.
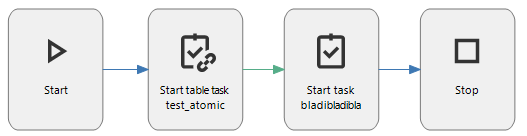
Hi Harm, What Robbert means it that the initial task execution only fills the XML parameter for you to use as input for the real task. By Starting a process flow with a dummy task that only obtains the selected row data in XML format, that way you can use that as input for the real task. The real task will still show a pop-up if there are any editable or read only fields.
Example
In the Table task you will obtain the selected row data in XML format. That will be outputted to a process variable. That process variable can then be used as input for the real task. Would that suffice or what key element are we not considering in this solution?
When executing a task for a selection of rows, the user interface first executes the context procedure for every single row to check if the user is allowed to execute the task for that row, and then executes the task for each permitted row. This can be quite time consuming, especially for web clients where the progress is also reported back to the client.
To speed up multirow task execution, a new feature has been developed to execute tasks for a selection of rows.
To enable multirow execution for a task:
Add an XML-typed parameter to the task
Make sure Popup for each row is switched off
Set the MultiselectParameterID extended property with the name of the parameter
With multirow execution enabled for a task, when the user interface executes the task, the specified XML parameter is filled with the parameter values for all rows. Even if only one row is selected.
The parameter is only filled when the task is executed. The XML is therefore not visible in the popup or available in the default and layout logic.
Be aware that both the default and the context logic are executed only once and not for every row. The parameter values for all rows are included in the XML, even if the context logic would have disabled the execution of the task for a specific row. The user interface also does not remove duplicate parameter rows when composing the XML, so you'll need to take care of that yourself.
In the task logic, use the XML parameter value instead of the regular parameters, for example:
T-SQL
1selectdistinct row.value('./param1[1]', 'int'), row.value('./param2[1]', 'varchar(10)')from@xml.nodes('/rows/row') as t2(row)
For information on working with XML data on SQL Server, see this link. More info on SQL XML programming for IBM i can be found here.
Page 1 / 2
This feature works very well in conjunction with drag-drop. When you drag multiple rows, you can have a multirow-task execute once with all the dragged rows.
Sounds great. But I can't quite see yet whether this would solve our issue where the process in question contains a http connector. The api we're talking to, only allows a single item to be requested every time. Which means the http connector needs to be ran for every item in the selection, which (if I read correctly) is still not possible.
Hi Pim, good question.
A possible solution would be to create a process flow in which you recursively store the values of the first row in process flow parameters, delete the row from the XML, and then call the HTTP connector using these parameters.
The SQL code for the task or process procedure to assign the parameters would look something like this:
code:
-- Store the values of the first row select @param1 = row.value('./param1[1]', 'int'), @param2 = row.value('./param2[1]', 'varchar(10)') from @xml_input.nodes('/rows/row[1]') as t2(row)
-- Delete the first row set @xml_input.modify('delete /rows/row[1]')
The HTTP connector should be called while the parameters have a value.
Also make sure you use a different name for the XML input parameter of the task than the MultiselectParameterID.
I don't think looping in processflows ever even crossed my mind. This could be a very nice solution.
One thing though, I would personally prefer keeping a pointer (int) to the current row, this would keep the input intact.
I had to fiddle around a bit, but here's an example of using a pointer:
code:
declare @pointer int = 1 while @pointer < 3 begin select row.value('(./param1[1])', 'int') , row.value('(./param2[1])', 'varchar(10)') from @xml.nodes('(/rows/row[sql:variable("@pointer")])') as t2(row)
set @pointer += 1 end
I'm trying something similar with the copy file process action to copy a batch of files by obtaining "from file" and "to file" values from a select query. I put all those rows in a table variable and then loop through these rows one by one. But this is the part that eludes me:
The HTTP connector should be called while the parameters have a value.
What happens now is that the loop finishes and ends up outputing a single set of null values. How can I insert a sql "while" loop into a process flow so that it outputs parameters set by set into the process variables?
Does this feature also work for reports?
I need to make a report with an output based on selected rows in a grid.
Does Multirow task execution still work from version 2020.1?
Does this feature also work for reports?
Reports currently don't support this. We should think about this in a design and investigate whether report implementations are able to process these kind of structured data.
I'd suggest to park this question in a separate post/idea to think about alternatives and to investigate the need for this.
In the future this feature will be configurable through the metamodel and will probably usetable valued parameters instead of XML. We'll be able to automatically upgrade the model, but you'll need to change the code yourself!
Gradually our codebase gets cluttered more and more with your originally suggested solution. Can you get us an update on when you expect the future will arrive on this matter?
@Ricky This is on our backlog, but we have not yet planned a date for this.
It is, however, trivial to locate and rewrite the select (and delete) from the XML to use a table valued parameter. And from a functional point of view, it doesn't make any difference.
Rickywrote:
Jasperwrote:
In the future this feature will be configurable through the metamodel and will probably usetable valued parameters instead of XML. We'll be able to automatically upgrade the model, but you'll need to change the code yourself!
Gradually our codebase gets cluttered more and more with your originally suggested solution. Can you get us an update on when you expect the future will arrive on this matter?
What we've currently have done is having everywhere the same structure of creating a temporary table, which should be replaceable with the actual solution. We’re everywhere using @multi_row as input and @record as actual table used.
On each template we apply it (almost all tasks), we do something like this:
1declare@recordtable (project_id id not null , part_id id not null)insert into@record (project_id , part_id) select x.value('(project_id)[1]', 'id') , x.value('(part_id)[1]', 'id')from@multi_row.nodes('rows/row') as t(x)
I hope for us that we by doing so we only need to remove the code above and can use the @records table.
Jasperwrote:
@Ricky This is on our backlog, but we have not yet planned a date for this.
It is, however, trivial to locate and rewrite the select (and delete) from the XML to use a table valued parameter. And from a functional point of view, it doesn't make any difference.
And how to deal with unit tests on multi rows? Currently I have a long input string (<rows><row><item>1</item></row><row><item>2</item></row></rows>), but that should be converted to some kind of other data structure allowing multiple rows at once? That is less trivial than find and replace?
Hi Ricky,
I hope for us that by doing so we only need to remove the code above and can use the @records table.
That is indeed how it will need to be modified.
And how to deal with unit tests on multi rows?
We will automatically convert these input strings to the required data structure.
Jasperwrote:
@Ricky This is on our backlog, but we have not yet planned a date for this.
It is, however, trivial to locate and rewrite the select (and delete) from the XML to use a table valued parameter. And from a functional point of view, it doesn't make any difference.
Hi @Jasper , can you tell a bit more about the table-valued parameters in general what the plans are? And in what period of time? As I can't find it in the ‘ideas’ backlog.
I assume the multi row solution will be replaced by that, but I think I have another case for which table valued parameters could be useful. But I'm not sure it's part of the same, or something new.
It could be useful when you could design them as ‘Domain’, so it can be used in tasks, subroutines and process flows. We currently use a lot of XML passing data in process flows, but handling XML is pretty heavy for SQL Server. It also could decrease our code base as it's no longer necessary to apply transformations from a table variable, to XML, and back from XML to a table variable.
I've created a custom validation to prevent having “Popup for each row” checked while using the multi row feature (which will result in a null value). For those who are interested;
1insert into validation_msg ( project_id, project_vrs_id, validation_id, pk_col_1, pk_col_2, pk_col_3, pk_col_4, pk_col_5, pk_col_6, pk_col_7, generated, insert_user, insert_date_time, update_user, update_date_time )select@project_id , @project_vrs_id , @validation_id , @project_idas pk_col_1 , @project_vrs_idas pk_col_2 , t.task_id as pk_col_3 , nullas pk_col_4 , nullas pk_col_5 , nullas pk_col_6 , nullas pk_col_7 , 1 , dbo.tsf_user() , sysdatetime() , dbo.tsf_user() , sysdatetime()from task twhere t.project_id =@project_idand t.project_vrs_id =@project_vrs_idand t.popup_for_each_row =1andexists ( select1from task_parmtr tp where tp.project_id = t.project_id and tp.project_vrs_id = t.project_vrs_id and tp.task_id = t.task_id and tp.task_parmtr_id = ( select top 1 epo.property_value from extended_property_overview epo where epo.project_id = t.project_id and epo.project_vrs_id = t.project_vrs_id and epo.extended_property_id ='MultiselectParameterID'and epo.runtime_configuration_id = ( -- default select rc.runtime_configuration_id from runtime_configuration rc where rc.project_id = t.project_id and rc.project_vrs_id = t.project_vrs_id and rc.default_configuration = 1 ) ) )
When I try to view the content of the variable with tsf_send_message it’s just empty for me.
Also the task still seems to be executed multiple times.
Can you help me with this?
Regards,
Peter
Hi pvleeuwen,
Can you please file a ticket in TCP for this? Thanks.
I have created a dynamic control_procedure which automatically generates a @xml_table for each task that has a parameter which is the same as the property_value of MultiselectParameterID.
The goal of this procedure is that we don't have to retrieve the XML manually for all the XML variables and we have the same xml_table for each task procedure, also when we add a new parameter to the table task, this will be added automatically. This way you can use the table @xml_table in the template code for the task, instead of reading out the XML parameter every time you need some data.
Code for the control_procedure (Assignment "SQL”, code group "TASKS”):
1--Definition of the MultiSelectParameterIDdeclare @extended_property_id extended_property_id = 'MultiselectParameterID'--Variable to save the value of the MultiSelectParameterIDdeclare @xml_variable property_value--Table to save the task_id's which have a MultiSelectParameterIDdeclare @task table (task_id task_id)--Retreive the tasks which have a task parameter, which have a MultiSelectParameterID connected.insert into @task (task_id)select t.task_id from task t where t.project_id = @project_id and t.project_vrs_id = @project_vrs_id and exists (select 1 from task_parmtr tp where tp.project_id = t.project_id and tp.project_vrs_id = t.project_vrs_id and tp.task_id = t.task_id and exists (select 1 from runtime_extended_property ep join runtime_configuration rc on rc.project_id = ep.project_id and rc.project_vrs_id = ep.project_vrs_id and rc.runtime_configuration_id = ep.runtime_configuration_id and rc.default_configuration = 1 where ep.project_id = tp.project_id and ep.project_vrs_id = tp.project_vrs_id and ep.extended_property_id = @extended_property_id and ep.property_value = tp.task_parmtr_id ) )--Retreive the value of the MultiSelectParameterIDselect @xml_variable = ep.property_value from runtime_extended_property ep join runtime_configuration rc on rc.project_id = ep.project_id and rc.project_vrs_id = ep.project_vrs_id and rc.runtime_configuration_id = ep.runtime_configuration_id and rc.default_configuration = 1 where ep.project_id = @project_id and ep.project_vrs_id = @project_vrs_id and ep.extended_property_id = @extended_property_id group by ep.property_value--Connect the task to the templateinsert into prog_object_item ( project_id ,project_vrs_id ,prog_object_id ,prog_object_item_id ,order_no ,control_proc_id ,template_id)select @project_id ,@project_vrs_id ,concat_ws('_','task',t.task_id) ,concat_ws('_','task',t.task_id,'xml_table') ,5 ,@control_proc_id ,@control_proc_id from @task t--Fill the variables.insert into prog_object_item_parmtr ( project_id ,project_vrs_id ,prog_object_id ,prog_object_item_id ,parmtr_id ,parmtr_value ,order_no ,no_line_when_empty)select @project_id ,@project_vrs_id ,concat_ws('_','task',t.task_id) ,concat_ws('_','task',t.task_id,'xml_table') ,'comma' as task_parmtr_id ,case when x.min_abs_order_no = tp.abs_order_no then ' ' else ',' end as parmtr_value ,tp.abs_order_no * 10 ,0 as no_line_when_empty from @task t join task_parmtr tp on tp.project_id = @project_id and tp.project_vrs_id = @project_vrs_id and tp.task_id = t.task_id cross apply (select min(abs_order_no) as min_abs_order_no from task_parmtr tpm where tpm.project_id = tp.project_id and tpm.project_vrs_id = tp.project_vrs_id and tpm.task_id = tp.task_id and tpm.task_id <> @xml_variable ) x where tp.task_parmtr_id <> @xml_variableunion allselect @project_id ,@project_vrs_id ,concat_ws('_','task',t.task_id) ,concat_ws('_','task',t.task_id,'xml_table') ,'task_parmtr_id' as task_parmtr_id ,tp.task_parmtr_id as parmtr_value ,tp.abs_order_no * 10 ,0 as no_line_when_empty from @task t join task_parmtr tp on tp.project_id = @project_id and tp.project_vrs_id = @project_vrs_id and tp.task_id = t.task_id where tp.task_parmtr_id <> @xml_variableunion allselect @project_id ,@project_vrs_id ,concat_ws('_','task',t.task_id) ,concat_ws('_','task',t.task_id,'xml_table') ,'dom_id' as task_parmtr_id ,tp.dom_id as parmtr_value ,tp.abs_order_no * 10 ,0 as no_line_when_empty from @task t join task_parmtr tp on tp.project_id = @project_id and tp.project_vrs_id = @project_vrs_id and tp.task_id = t.task_id where tp.task_parmtr_id <> @xml_variableunion allselect @project_id ,@project_vrs_id ,concat_ws('_','task',t.task_id) ,concat_ws('_','task',t.task_id,'xml_table') ,'xml_variable' as task_parmtr_id ,@xml_variable as parmtr_value ,10 ,0 as no_line_when_empty from @task t
Result of a task which has XML as task parameter ID and has “order_line_id” and "shipping_order_id” as parameter in task parameter.
1declare@xml_tabletable ( order_line_id id ,shipping_order_id id)insert into@xml_table ( order_line_id ,shipping_order_id)select row.value('./order_line_id[1]', 'id') ,row.value('./shipping_order_id[1]', 'id')from@xml.nodes('/rows/row') as c(row)
Very unfortunate that the multiselect parameter remains empty in default procedures. Is there a specific reason for that? And can we expect this to become available in the future?
I understand it can be complex, but just having the initial values of table parameters available in the multiselect parameter of the default procedure would help a lot to make multiselect tasks even more powerful.
Harm Horstmanwrote:
Very unfortunate that the multiselect parameter remains empty in default procedures. Is there a specific reason for that? And can we expect this to become available in the future?
I understand it can be complex, but just having the initial values of table parameters available in the multiselect parameter of the default procedure would help a lot to make multiselect tasks even more powerful.
Hi Harm,
I would imagine that it remains empty because the default is executed per row and not per set.
What is the usecase in which you need the xml parameter in the default?
I am working on a advanced multi row update task.
The default values I wish to set in my task depend on field values of all selected rows and I also like to inform the user about the affected rows before he/she executes the task.
Harm Horstmanwrote:
I am working on a advanced multi row update task.
The default values I wish to set in my task depend on field values of all selected rows and I also like to inform the user about the affected rows before he/she executes the task.
Setting the default value would be as easy as in the execution of the task right? Because the default value is not visible for the user anyway there.
And I think you could use a procesflow for this. Execute multi row task → show message → yes → execute task → no → abort
Does this help?
No, this is not what I want. Using a process flow is not desirable, because it will not give the desired result.
I need to now row data of all selected rows to set my task parameters. This to inform the end user better before he/she executes the task.
I don't think this is possible with the current implementation.
For now the only solution I see is to use a procesflow which could give you what you want, informing the user before the execution.
No, this is not what I want. Using a process flow is not desirable, because it will not give the desired result.
I need to now row data of all selected rows to set my task parameters. This to inform the end user better before he/she executes the task.
Hi Harm, What Robbert means it that the initial task execution only fills the XML parameter for you to use as input for the real task. By Starting a process flow with a dummy task that only obtains the selected row data in XML format, that way you can use that as input for the real task. The real task will still show a pop-up if there are any editable or read only fields.
Example
In the Table task you will obtain the selected row data in XML format. That will be outputted to a process variable. That process variable can then be used as input for the real task. Would that suffice or what key element are we not considering in this solution?
We use 3 different kinds of cookies. You can choose which cookies you want to accept. We need basic cookies to make this site work, therefore these are the minimum you can select. Learn more about our cookies.















 In the future this feature will be configurable through the metamodel and will probably use
In the future this feature will be configurable through the metamodel and will probably use